
HTTP status codes: all error and status codes
Every page we visit or link we click on triggers a series of requests and responses between our browsers and the servers that host the content: the “language” of this information exchange are HTTP status codes, essential and “invisible” elements that signal whether a request has been successful or if there have been hitches. The classic 404 error, 301 redirects, or internal server error 500 may appear to some people simply as seemingly meaningless numbers, but to the more experienced they are clear indicators of the quality of interaction between users, websites, and search engines. So let’s find out how status codes and especially error codes affect SEO and site performance in Google Search.
What HTTP status codes are
An HTTP status code is the server’s response to a browser request, identified by a three-digit code.
More precisely, HTTP status codes are short numeric messages that the server sends to the browser to communicate the outcome of a web request.

These codes, also known by the English name of status codes, are an integral part of the HTTP protocol, the standard language that enables communication between the client (our browser) and the server (where websites reside). Each code consists of three digits and is divided into five classes, each identified by the first digit: 1xx for information, 2xx for success, 3xx for redirects, 4xx for client errors, and 5xx for server errors. These numbers are not simply traffic signals, but true health indicators for each of our online actions.
Knowing what HTTP status codes are and what they mean, and thus also detected by our SEO spider, is in fact of paramount importance for site managers and SEO specialists, because it allows them to understand how site navigation actually works, whether there are problems in reaching certain resources or whether certain errors can affect page ranking.
What HTTP codes mean
Codes signal the response that a site’s server has generated to a specific HTTP request from a browser: depending on the type, this action may be completed successfully or, on the contrary, may be blocked by an error. For users, some forms of errors are visible, such as 404 or 503, for which HTML pages are automatically created on the browser, while other problems are invisible and traceable only through deeper scans with specific tools such as SEO audits.
HTTP Status Codes: why they are used and what information they give
HTTP status codes can become essential tools for monitoring and maintaining a site, because they can show hidden pitfalls that undermine the efficiency of our project.
In particular, their analysis allows even an SEO beginner to get immediate feedback on whether or not a query is successful, and thus understand whether his pages are working properly or need immediate action.
To put it more simply, a success code, such as the famous 200 OK, confirms that everything is working as it should; an error code, on the other hand, signals that something is wrong, allowing timely action to be taken. For users, these codes are often hidden, but when something does not work, they are exposed in the form of error messages, guiding the user toward understanding the problem. In addition, search engines use these codes to determine the health of a web page, thus affecting its ranking in search results.
How to analyze HTTP status codes
Analyzing HTTP codes is a common practice for those who manage websites and engage in optimization, and there are several ways to view this information, depending on the level of detail and the type of analysis we intend to perform. Developers, for example, can view status codes directly through the development tools built into modern browsers, such as Chrome or Firefox, which show the requests and responses exchanged between client and server. For more in-depth analysis, one can use specific software such as Wireshark or server monitoring tools such as cPanel or Plesk, which record logs of HTTP requests.
For those involved in SEO, platforms such as Screaming Frog or SEOZoom itself allow scans of websites to identify status codes and understand their impact on search engine rankings. These tools are particularly useful for identifying page accessibility issues, redirect chains or broken links that can negatively affect user experience and, consequently, site ranking.
Error codes: what they are and what they mean
HTTP error codes that fall into classes 4xx and 5xx signal specific problems that may occur when a user attempts to access a web page.
These are the so-called error codes or error codes, the ones that (inevitably) attract the most attention because they are warning signs about the health of our site. Turning the information to the positive, from a strategic point of view error codes can also become starting points for investigations and optimizations that can significantly improve the user experience and the performance of our online project.
As we will later see in more detail, 4xx codes indicate client-side errors, i.e., problems that result from incorrect or unauthorized requests sent by the user, while 5xx codes refer to server-side errors, i.e., problems that affect the operation of the server hosting the website.
The famous 404 Not Found is perhaps the most well-known among users, indicating that the requested page does not exist or is no longer available. But there are many others: 403 Forbidden signals that access to a resource is prohibited, 500 Internal Server Error indicates a generic server-side problem, and 503 Service Unavailable suggests that the server is temporarily unavailable, perhaps due to overload or maintenance.
Understanding the meaning of these codes is essential to maintain a functional and accessible website, and to ensure a good user experience. In addition, proper error handling can help preserve the SEO value of pages, preventing search engines from penalizing the site for technical problems.
The five categories of status codes
Based on the type of response, five main status code response categories are identified, identified by the first digit of the code:
- 1xx: Informational. The server informs the client that the request has been received and that the information processing is in progress.
- 2xx: Success. The operation was successfully completed. Thus, the server has received, processed, and accepted the client’s input, and the user typically views the requested web page or resource directly.
- 3xx: Redirection. The server receives the request, but other client-side actions and steps are required to complete it properly, because forwarding and redirection are present.
- 4xx: Client Error. This is the first category of error: the request cannot be completed because there are client-side problems, such as incorrect syntax or removed page. The user displays an automated html page reporting the error.
- 5xx: Server Error. This type of code reports server-side problems, which does not allow a seemingly valid request to complete correctly. The server error may be temporary or permanent, and again the user receives an html page reporting the circumstance.
A guide to the main HTTP status codes
Having completed the general overview, let’s go to see what are the main status codes that occur in the course of running a Web site, those that it is essential to know (and possibly correct) to avoid problems on the SEO side. Instead, the image shows the most comprehensive list of HTTP status codes, including the less frequent ones.

- Status code 200: OK. This is the normal and regular response in the dialogue between server and browser, because it indicates that everything is working properly: all requested data has been identified on the web server and transmitted to the client without problems. Visitors, bots and spiders find no errors and navigate the pages smoothly.
- Status code 301: Permanent redirect. The server notifies that the requested resource has been permanently moved to a new page via permanent redirect: users do not see the code, but the requested URL is automatically changed on the address bar and the old one is no longer valid. As we will see, handling this action has a strong influence on SEO.
- Status code 302: Temporary redirect. In this case, the resource transfer is temporary: the server moves visitors and bots to the new page, but the old page and the old address, however, remain valid.
- Status code 404: Page not found. We have devoted a specific article to this error, so we can simply remind you that status code 404 indicates that the requested page data has not been located on the server.
- Status Code 410: Gone. This is a more definitive error than the previous one, because it signals that the page is not only no longer available at the moment, but also that it will not be available in the future. All links pointing to a 410 page lead bots and users to dead resources, so for better management you need to remove all references from the content.
- Status Code 500: Internal Server Error. Having problems is not only the pages of the site, but the server itself, which fails to fulfill a seemingly valid request. Error 500 signals generic and unexpected server problems, which prevents proper access to the site.You need to analyze the type of problem and try to figure out if any interventions, repairs, or reports to the server are needed to restore the situation to normal.
- Status Code 503: Service Unavailable. The referring server is down, overloaded, or otherwise temporarily down (including for maintenance work): code 503 signals search engines to come back soon because the page or site will only be down for a short time.
Google’s guide on the SEO effects of HTTP status codes
As mentioned, Google also published a resource on its Search Central site to clarify some issues on the topic, describing precisely “how different HTTP status codes, network errors, and DNS errors affect Google Search.”
Specifically, it covers the top 20 status codes that Googlebot encountered on the Web and the most important network and DNS errors-meaning, therefore, that there is no room for the more peculiar and bizarre status codes, such as the 418 I’m a teapot, which has become a favorite easter egg among developers. In addition, all problems mentioned on the page generate a corresponding error or warning in the Page Indexing report.
The document is divided into three sections-namely, HTTP Status Codes, Network Errors, and DNS Errors-offering a descriptive introduction on the topic, with up-to-date information and, most importantly, interesting details on how Google reacts to various situations. For example:
- Google will try 10 hops for redirects, after which it will consider the URL with a redirect error in Search Console.
- Redirect 301 vs 302: For Google, a 301 redirect is a strong signal that the redirect target should be canonical, while a 302 redirect is a weak signal that the redirect target should be canonical.
- The 200 status codes guarantee that the page goes to the indexing pipeline, but they do not guarantee that the page is then actually indexed.
Google and HTTP status codes
HTTP status codes, the paper reminds us, are generated by the server hosting the site when it responds to a request made by a client, such as a browser or crawler. Each HTTP status code has a different meaning, but often the outcome of the request is the same. For example, there are multiple status codes that signal redirection, but their practical outcome is the same.
Search Console generates error messages for status codes in the range 4xx-5xx and for failed redirects (3xx). If the server responded with a 2xxstatus code, the content received in the response can be considered for indexing (but, as we said, there is no guarantee that it will then actually be included in the index).
Status code 2xx (success)
Google considers the content for indexing. If the content suggests an error, such as a blank page or an error message, Search Console will show a soft 404 error.
- 200 (success / success)
- 201 (created / created)
In both of these cases, Googlebot passes the content to the indexing pipeline. The indexing systems can index the content, but this is not assured.
- 202 (accepted / accepted)
Googlebot waits for content for a limited time, then passes everything it has received to the indexing pipeline. The timeout depends on the user agent: for example, Googlebot Smartphone might have a different timeout than Googlebot Image.
- 204 (no content / no content)
Googlebot reports to the indexing pipeline that it has received no content. Search Console may show a soft 404 error in the site index coverage status report.
Status code 3xx (redirects)
Googlebot follows up to 10 redirects, as mentioned: if the crawler does not receive the content within 10 hops, Search Console will show a redirect error in the site index coverage report. The number of hops Googlebot follows depends on the user agent, and for example, Googlebot Smartphone might have a different value than Googlebot Image.
Google also reports that in the case of robots.txt it follows at least five redirect hops as defined by RFC 1945, so it stops and treats it as a 404 error for the robots.txt file.
In addition, although Google Search treats some of these status codes in the same way, it must be considered that they are semantically different: therefore, the advice is to always use the appropriate status code for redirection so that other clients (e.g., e-readers, other search engines) can take advantage of it.
- 301 (moved permanently / moved permanently)
Googlebot follows the redirection and the indexing pipeline uses the redirection as a strong signal that the redirection target should be canonical.
- 302 (found / trovatp)
- 303 (see other / see other)
In both cases, Googlebot follows the redirection and the indexing pipeline uses the redirection as a weak signal that the redirection target should be canonical.
- 304 (not modified / not modified)
Googlebot signals to the indexing pipeline that the content is the same as the last time it was crawled. The indexing pipeline can recalculate the signals for the URL, but otherwise the status code has no effect on indexing.
- 307 (temporary redirect / temporary redirection).
Equivalent to the 302 code.
- 308 (moved permanently / stayed permanently).
Equivalent to code 301.
Status code 4xx (client errors)
Client errors are defined as status codes in the 4xx range: in these cases, Google’s indexing pipeline does not consider for indexing URLs that return such a status code, and URLs that are already indexed and return a 4xx status code are removed from the index.
More precisely, all 4xx errors except 429 are treated the same way: Googlebot notifies the indexing pipeline that the content does not exist. The indexing pipeline removes the URL from the index, if it has been previously indexed, while new 404 pages encountered are not processed. The crawl frequency gradually decreases.
Google also urges against using 401 and 403 status codes to limit crawl rate: apart from 429, 4xx status codes “have no effect on crawl rate,” the document clarifies.
- 400 (bad request / bad request)
- 401 (unauthorized / unauthorized)
- 403 (forbidden / prohibited)
- 404 (not found / not found)
- 410 (gone / removed)
- 411 (length required / length requested)
- 429 (too many requests / excessive requests)
Googlebot treats status code 429 as a signal that the server is overloaded, considering it a server error.
Status code 5xx (server errors)
Server errors 429 and 5xx prompt Google’s crawlers to temporarily slow down crawling; URLs that have already been indexed are retained in the index, but are eventually dropped.
In addition, if the robots.txt file returns a server error status code for more than 30 days, Google will use the last cached copy of the robots.txt; if not available, Google assumes no crawling restrictions.
- 500 (internal server error / internal server error)
- 502 (bad gateway)
- 503 (service unavailable / service unavailable)
In all these cases, Googlebot reduces the site crawl frequency: this decrease is proportional to the number of individual URLs that return a server error. Google’s indexing pipeline removes URLs that persistently return a server error from the index.
What are soft 404 errors
At the end of June 2022, the guide was further enriched with another paragraph, dedicated to a topic that returns often in SEO discourse, namely so-called soft 404 errors.
A soft 404 error occurs when a URL returning a page tells the user that the page of interest does not exist and also a status code 200 (success). In some cases this is a page with no main content or a blank page.
These pages can be generated for various reasons by the web server, the website’s content management system, or the user’s browser. For example:
- A missing server-side include file.
- A broken database connection.
- An empty internal search results page.
- An unloaded or missing JavaScript file.
Returning a 200 (success) status code but then displaying or suggesting an error message or some type of error on the page constitutes a negative user experience. Users may think the page is up and running, but then come across some type of error. These pages are excluded from Search.
When Google’s algorithms detect that the page is actually an error page based on its contents, Search Console shows a soft 404 error in the URL Indexing report.
How to correct soft 404 errors
Depending on the state of the page and the desired result, soft 404 errors can be addressed and resolved in different ways, identifying the best solution for our users.
- The page and content are no longer available
If we have removed the page and there is no replacement with similar content on the site, a 404 (not found) or 410 (gone) response status code for the page is more appropriate, indicating to search engines that the page does not exist and that the content should not be indexed.
If we have access to the server configuration files, we can customize these error pages and make them useful to users: an optimal custom 404 page allows users to find the information they are looking for and also provides them with other useful content that encourages them to continue browsing the site.
Google also provides some suggestions for designing a useful custom 404 page:
- Clearly communicate to visitors that the page they are looking for was not found, using simple, friendly language.
- Check that the 404 page has the same look and functionality (including navigation) as the rest of the site.
- Add links to the most-read articles or posts on the site, as well as a link to the home page.
- Allow users a method to report inaccessible links.
Custom 404 pages are created exclusively for users: since they are useless from the point of view of a search engine, it is important that the server return an HTTP 404 status code to prevent them from being indexed.
- The page or content is now located elsewhere
If the page has been moved or there is a page that clearly replaces it within the site, a 301 (permanent redirect) code should be returned to redirect the user so as not to interrupt their browsing experience and take advantage of “a great way to tell the search engines about the new location of the page.” We can use the URL Inspection tool to check if the URL actually returns the correct code.
- The page and content still exist
If a valid page on the site was marked with a soft 404 error, it is likely that it was not loaded correctly for Googlebot, key resources were not loaded, or an error message was displayed prominently during rendering.
If the displayed page is empty, nearly empty, or the content has an error message, it is possible that it refers to many resources that are impossible to load (images, scripts, and other non-textual elements), which can be interpreted as a soft 404 error. Reasons why resources cannot load include: blocked resources (from the robots.txt file), too many resources on the page, various server errors, or resources that are very large and/or load slowly.
SEO management of HTTP errors
This quick and concise framework allows you to know the main status queues and identify and diagnose site errors in time, so you can avoid harmful “wasted time” to fix problems. For example, type 4xx responses affect proper navigation by people (and Googlebot-type crawlers) and may depend on internal site errors, so work must be done to find out what the causes are, correct any changes made to URLs, or improve deleted page paths.
How to use 301 redirects effectively
Some of these codes are also an SEO tool, such as the 301 redirect, which is often used to move crawlers and users from an important page on the site to an equally relevant resource. According to SEO theories, Google appreciates and gives more credit to redirects via 301 than other methods for transferring link juice from the deleted page to the new one, whereas 302 (temporary redirect), on the other hand, may not guarantee the same transition because search engine crawlers treat this information as temporary and still give weight to the old page.
In the case of a 404 error, then, one has to evaluate the reach of the individual page: if it was authoritative, with a lot of traffic and links acquired, it might be the case to use a 301 redirect to a page relevant in content. Only in this way could Google pass link equity to the new resource. Conversely, if these are pages that are not very useful, poorly searched and never linked to, it might be more useful to return a 404 on purpose, which will prevent them from being subjected to indexing and repeated crawl attempts by search engine crawlers.
Google’s SEO guide to network problems and DNS errors
But it is not only status queues that we need to worry about, and in fact Google also pays special attention to network and DNS errors, which have quick and negative effects on a URL’s presence in Google Search.
Googlebot treats network timeouts, connection recovery, and DNS errors similarly to 5xx server errors. In the case of network errors, scanning immediately begins to slow down, since a network error is a sign that the server may not be able to handle the service load. Already indexed URLs that are unreachable will be removed from Google’s index within a few days. Search Console can generate errors for each respective error.
Debugging network errors
Network errors (network errors) occur before Google starts crawling a URL or while crawling the URL. Because they can occur before the server can respond, there is no status code that can suggest problems, and therefore diagnosing these errors can be more challenging.
The error can be in any component of the server that handles network traffic. For example, the paper says, overloaded network interfaces can drop packets and lead to timeout (inability to establish a connection) and connection reset (RST packet sent because a port was closed in error).
To debug timeout and connection reset errors Google suggests:
- Look at the firewall settings and logs, because there may be too large a set of blocking rules.
- Look at network traffic. Use tools such as tcpdump and Wireshark you can capture and analyze TCP packets and look for anomalies pointing to a specific network component or server module.
- Contact the hosting company if nothing suspicious is found.
Debugging DNS errors
Usually, DNS errors depend on misconfiguration, but they can also be caused by a firewall rule blocking Googlebot DNS Queries.
To debug DNS errors, Google invites the following steps:
- Check firewall rules: none of Google’s IP addresses should be blocked by firewall rules, and UDP and TCP requests should be allowed.
- Examine the DNS records, to verify that the A and CNAME records are respectably addressing the correct IP addresses and hostnames, as shown in the image.

- Verify that all name servers point to the correct IP addresses for the site, as shown in the image.
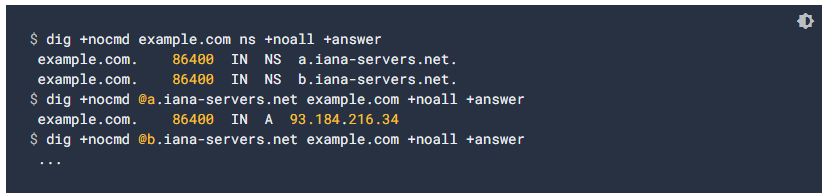
- Wait for propagation of changes: if we have made changes to the DNS configuration in the last 72 hours, we may need to wait for the changes to propagate into the global DNS network. To speed up propagation, we can clear Google’s public DNS cache.
- Check the DNS server: If we run our own private DNS server, we need to make sure it is intact and not overloaded.

