
Page Rendering: how it happens and why search engines need it
The stages of discovery and analysis of web pages by search engines not only takes the form of the indexing process that we are already familiar with, but there is another decisive moment in which crawlers come into contact with what we publish: it is the rendering, the operation of interpreting and rendering the page graphically, which plays a crucial role in the way websites are viewed and indexed by search engines. This process may seem technical and complex, but it is important to understand it (at least superficially) because it is an essential component in ensuring that our website content is easily accessible and visible to both users and the search engines themselves. And so, with this quick guide we discover precisely how rendering works, why it is needed by search engines, and how it can affect SEO.
What is the rendering
Literally, rendering is the graphic encoding of the information on the page in HTML language, which are translated (rendered) so as to give an understandable form to the graphic elements that make up all the websites, each with its own characteristics.
In other words, in the Web context, the term rendering refers to the process by which search engines, such as Google, interpret and display the HTML code of a Web site in order to “see” the Web site in a manner similar to how a human visitor would see it, in order to then properly proceed to the stage of adding it to specific indexes.
To allow this process are the special rendering engines, rendering engines, which collect and digest the data packets coming from the server and transform the lines of code of the HTML language into graphical and functional elements, such as text blocks with hyperlinks, images, videos and other elements such as PDF files.
The keywords of rendering: definitions and clarifications
In more technical terms, rendering is the process of executing the JavaScript code of a web page to generate the visual layout we see when we visit a site: this process can be performed either on the client side (i.e., in the user’s browser) or on the server side.
Rendered HTML is more widely known as DOM, an abbreviation for Document Object Model: every web page has a DOM, which represents the initial HTML plus any changes made by JavaScript called from the HTML.
Client-side rendering means that the JavaScript code is executed in the user’s browser, which can take more time and resources; on the other hand, server-side rendering means that the JavaScript code is executed on the server before the page is sent to the user’s browser. This can speed up the loading of the page, but requires more resources from the server.

As web.dev experts explain, however, in order to best understand and use different architectures, it is important to first know the precise terminology to use when talking about them. In particular, there are some “key words” and acronyms we need to familiarize ourselves with, which also refer to specific technical approaches:
- Server Side Rendering (SSR): rendering of a client-side or universal HTML app on the server. This technique requires the server to generate the entire HTML page before sending it to the user’s browser, improving page load times and indexing by search engines, but also risking strain on server resources.
- Client Side Rendering (CSR): rendering an app in a browser using JavaScript to modify the DOM. The user’s browser runs JavaScript to generate the HTML page: this can provide an interactive user experience, but it can slow down load times and make it harder for search engines to index the site.
- SSG (Static Site Generation): HTML pages are generated in advance, during the build phase of the site, and saved as static files. This can offer very fast loading times and excellent SEO, but can be less flexible for sites with dynamic content.
- ISR (Incremental Static Regeneration): is a hybrid technique that combines SSR and SSG. With ISR, pages are generated statically during the build phase, but can be “regenerated” on an incremental basis when data changes. This provides a good balance between performance and flexibility.
- DSR (Distributed Static Rendering): DSR is another hybrid technique that combines elements of SSR and SSG. With DSR, pages are statically generated and distributed over a content delivery network (CDN) for fast loading. However, pages can also be dynamically regenerated in response to specific events or triggers.
- ESR (Edge Side Rendering): This technique involves rendering taking place “at the edge,” that is, as close to the end user as possible, usually on a server in a content distribution network (CDN). This can greatly improve page load times as content is rendered and served from a location geographically close to the user. ESR is particularly useful for sites with a high degree of user customization or dynamic content.
- PRPL (Push, Render, Pre-cache, Lazy-load): This is a performance optimization strategy to improve page loading. It consists of “pushing” critical resources as early as possible, “rendering” the initial UI, “pre-caching” the remaining resources, and “lazy-loading” other resources as they become necessary.
- Rehydration: “bootstrapping” JavaScript views on the client in such a way as to reuse the tree and DOM data of the HTML rendered by the server.
- Prerendering: running a client-side application at compile time to acquire its initial state as static HTML.
From a performance perspective, however, the metrics of interest (and interest) are:
- Time to First Byte (TTFB), seen as the time between clicking on a link and the arrival of the first bit of content. In most cases, problems with TTFB originate from poor performance of the server on which the Web site is hosted, but sometimes even where the Web site renders javascript or JS can lead to criticality; more server-side rendering since information must be retrieved from a server from a location other than the computer to render the page content.
- First Contentful Paint (FCP), the moment when the requested content (body of the article, etc.) becomes visible. Performance annoyances with First Paint typically occur when there is a big problem on the CSS and JS side of things of which are trying to load unnecessary scripts and actions to load the site in a fast past. All of this negatively impacts FCP, for example, while other problems can arise from the way the data is processed: SSR generally has a more consistent loading speed, both because it has repeatable hardware than CSR, and because there are a variety of devices that can affect how fast a page can retrieve and load content into the DOM.
- Interaction to Next Paint (INP), seen as a representative metric that assesses whether a page responds consistently and quickly to user input.
- Time to Interactive (TTI), which measures when a page becomes interactive: if something is heavily dependent on JS, it can further delay page speed and hinder performance.
- Total Blocking Time (TBT), a proxy metric for INP, which calculates the amount of time the main thread was blocked while the page was loading.
Rendering and SEO: why you need to be careful
Google cannot index what it cannot display: this simple consideration is enough to understand the crucial value of page interpretation and graphical rendering with respect to the fate of the site on the search engine.
In fact, when we think of page ranking, indexing immediately comes to mind, says Dave Davies on SEL pages, and specifically at the time when a search engine has already:
- Discovered a page by sitemap or crawling.
- Continued to visit the page for indexing.
- Collected all the content on the page.
- Started ranking the page for queries.
This is probably the most important stage of the process because these are the factors that influence the rankings, but it is not the final stage of the discovery process and, according to Davies, its weight may be diminishing over time as the final stage-that is, rendering-gains traction.
How and, more importantly, where the rendering process takes place can in fact have a significant impact on user experience, site performance and search engine optimization (SEO). As Google’s Martin Splitt said, Web page rendering is what happens between the browser and the Web page, the process of creating a Web page: an efficient rendering process results in high Core Web Vitals scores, while conversely, a less efficient rendering process can affect sales, advertising revenue, and even Web page crawling to some extent.
The importance of rendering for SEO
Rendering is closely related to SEO, as it affects whether and how search engines interpret and index a website’s content: taking it to extremes, good rendering can improve a site’s visibility in search results, while inefficient rendering can hide important content from search engines.
For example, if a website makes heavy use of JavaScript to generate its content, and this content is not properly rendered, search engines may not be able to “see” and thus index this content, and this is then likely to result in reduced visibility of the site in search results.
We must then also be aware of the negative effects of expensive rendering for users, because it may affect visitors browsing the site from older phones, causing problems viewing the page, but also on newer devices, which may have problems downloading a Web page if it has been active for days and RAM is spread across multiple open browser windows.
For these reasons, too, it is important to optimize website rendering for SEO, through the use of techniques such as server-side rendering or prerendering, which generate a static version of the page that can be easily indexed by search engines.
In fact, rendering options are many and certainly should not all be used on the same project, partly because the choice also depends on elements such as the technologies used, such as the hosting platform and frontend framework. Also, when deciding on an approach to rendering, we should start by measuring and understanding what the bottlenecks are, considering, for example, whether static rendering or server-side rendering might be right for us, or whether to ship mainly HTML with minimal JavaScript to achieve an interactive experience.
The advice coming from web.dev developers is to analyze the pros and cons and the fit of different rendering approaches to our projects and the types of sites we create, so that we make more informed choices about tools and technologies, rather than letting those choices dictate our approach.
How to optimize Rendering for SEO, basic tips
To optimize site rendering for SEO, it is important to make sure that crucial site content is easily accessible and indexable by Google.
A first method to achieve the goal is to understand, and possibly implement, techniques such as server-side rendering (SSR), static site generation (SSG), or prerendering, which generate a static version of the page that can be easily indexed by Google. In particular, static rendering techniques can be particularly effective because they generate a static version of the page during the site build phase, which can be easily indexed by search engines and offer very fast loading times and excellent SEO; the critical aspect is that it can be less flexible for sites with dynamic content.
In these cases, sites with dynamic content, hybrid rendering techniques, such as incremental static rendering (ISR) and distributed static rendering (DSR), should be evaluated and can offer a good balance between performance and flexibility. These techniques combine elements of SSR and SSG, generating static pages that can be easily indexed by search engines, but can also be dynamically regenerated in response to specific events or triggers.
Again, it is critical to monitor and test your site regularly to ensure that the rendering is optimized for SEO: tools such as Google Search Console can help you identify any rendering problems and get suggestions on how to fix them.
A final general, and always valid, tip is to minimize the use of JavaScript, which, although powerful and versatile, can also slow down Google’s rendering and indexing process. Therefore, you should minimize its presence, especially for crucial site content and functionality and, if possible, try to provide a static HTML version of the content, which can be easily indexed by Google.
How rendering engines work
There are essentially three phases in which the work of a rendering engine is composed:
- Decoding of inputs – or input information.
- Data processing.
- Graphic representation of information.
Trying to simplify, the web rendering engine picks up the source code of the web pages requested by the user and scans all the HTML and CSS elements present; these information are then decoded to start building the web page to display.
In this process are identified the various parts of which the page is composed, such as the text block and its formatting, the background, the color, the content, the various multimedia elements and so on. Using the information in the source code of the resource and in the CSS file, the engine processes and tidies the elements and then, together with the GPU, transforms the source code into the elements actually displayed in the browser tab, finally allowing the user to access and consult correctly the desired resource.
Differences between rendering and indexing
The difference between rendering and indexing can be represented very easily with a comparison between two images, explains Davies: at the top we have the lines of HTML code of a page of our blog, while at the bottom there is the graphical representation of the same page as displayed in the browser.
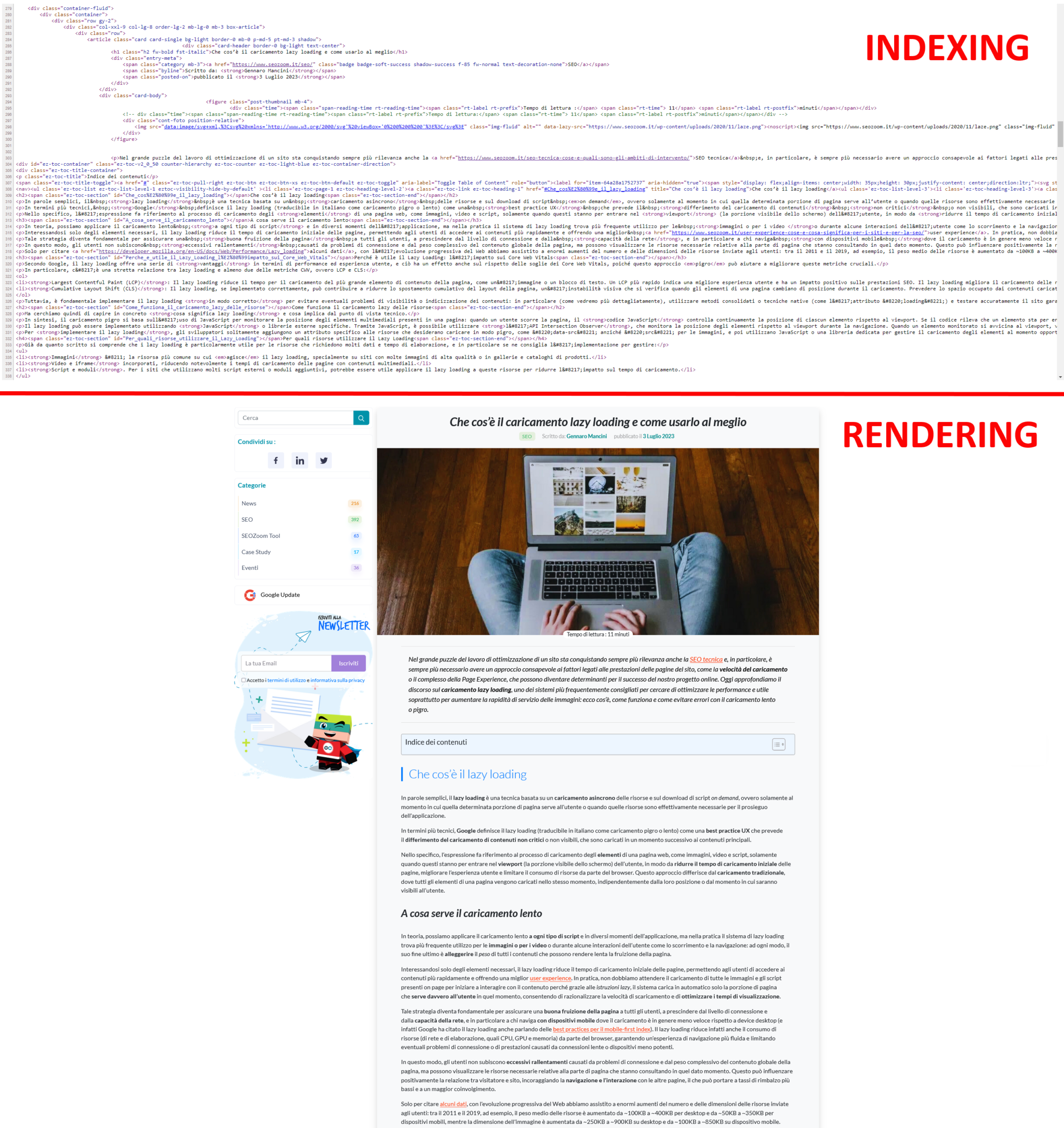
Basically, it is the same content, first shown for how it looks during indexing (HTML) and then for how it is rendered in rendering (Chrome).
It is Jamie Indigo who takes these concepts further, explaining that rendering is the process in which Googlebot retrieves pages from our site, runs the code, and evaluates the content to understand the layout or structure of the site. All the information gathered by Google during the rendering process is then used to rank the quality and value of the site’s content against other sites and what people are searching for with Google Search.
Each web page essentially has two states, and a website be very different between the two states:
- Initial HTML, which occurs first. This is the server’s response: it contains HTML and links to resources such as JavaScript, CSS, and images needed to create the page. To see the initial HTML, just view the source code of the page.
- Rendered HTML, more widely known as DOM (short for Document Object Model). Every web page has a DOM: it represents the initial HTML plus any changes made by JavaScript called from the HTML. To view the DOM, we need to open the browser developer tools in our browser and click on the console tab.
Why rendering is important
You might think that rendering is important only for those who have Javascript sites, but in reality this process concerns and affects all sites, as confirmed by the fact that the search engines rendered pages even before the recent boost to the use of Javascript for websites.
Essentially, the reason this process matters is that rendering provides the truth.
Through the code, a search engine can understand what a page is about and roughly what it contains. With rendering, they can understand the user experience and have much more information about which content should have priority.
During the graphical rendering phase the search engine can answer many relevant questions to properly understand a page and how it should be classified. For example, the article mentions issues such as:
- Is the content hidden behind a click?
- Is an ad filling the page?
- Is the content displayed at the bottom of the code actually displayed at the top or in the navigation?
- Is a page loading slow?
When the rendering actually happens
According to the information in our possession – and always in principle – the rendering occurs after indexing and may even take a few days or weeks, with a variable time sequence. This essentially means that search engines will understand the content and context of a page before they get a full understanding of how this should be prioritized.
This obviously does not mean that search engines are completely ignorant until rendering, because there are some solid rules and impressions that they have acquired over the years that allow them to quickly make assumptions about:
- Which elements are present.
- Where they are located.
- How important they are to the user.
But it is only after the graphic rendering of the pages that the engines will know that their assumptions are correct and can fully understand a page and its shape.
Problems with rendering
In summary, search engines send a crawler to the site, which will represent the page as a browser would.
If in Bing “they seem to be a little better at rendering, which is interesting”, at home Google Googlebot has a Web Rendering Service (WRS) component, updated in May 2019, on the occasion of the evergreen update of the crawler, which now also uses the latest version of Chrome for rendering.
Until then, the WRS used version 41 of Chrome, which was exceptional for compatibility but “was a nightmare for sites that relied on modern functionality, such as those of modern Javascript“, writes Davies.
In essence, this means that “when your page is rendered by Googlebot it is rendered more or less as you would see it in your browser“. However, it is wrong to think that it is enough to check on a browser if the page works properly, because the sense of rendering is other.
If we have a “basic site with predictable HTML and almost zero dynamic contents, there is really nothing to worry about” and probably there were no worries even with the old WRS configuration.
But for sites “with dynamic contents offered via Javascript, there is a big warning and it is rooted in a gap”: until the page is displayed, the engine does not know what is on it. Unlike a site with a simple HTML output – in which the engine might lose some of the context but includes the content – with a site based on something like Javascript that is based on rendering “the engine will not know what content is on the page until the WRS has completed its work“.
And so, the “weeks” of work required to achieve this result are quite impactful, and it is also for this reason that the engines are working to reduce latency. Until then, however, Javascript developers will have to rely on pre-rendering (creating a static version of each page for engines), which is by no means the ideal solution.
How Web Rendering Service works
The rendering life cycle follows this path:
- A page is discovered by sitemap, crawler, etc.
- The page is added to the list of pages on the site to be scanned when the crawl budget is available.
- The content of the page is scanned and indexed.
- The page is added to the list of pages to render on a site when budget rendering is available.
- The page is rendered.
The critical and unspoken element of the process is the rendering queue: “Googlebot could reach a page weeks before rendering and until then some content (Javascript sites) or context (all sites) might be missing”, explains the article. And when a page reaches the top of queue rendering, the engine will send what is called headless browser, or a browser without a graphical user interface.
Somehow, however, the search engine manages to figure out what where and how it appears on a page, even if it has no eyes to see it: when the process is completed in a positive way, “the rendered version will look like Googlebot and in the graphical browsers”, while “otherwise, the page is likely to be based on an unsupported function such as a user’s permission request”.
Rendering is still problematic
According to Davies, at the moment “we can count on the indexing capabilities of the engines, but the rendering side still has a long way to go” to bridge the gap between what search engines see and what a user’s browser does.
Based on the author’s experience, there is a possibility that in the short-to-medium term “the latency between indexing and rendering is drastically reduced, especially on sites that are based on this process”, and this could lead to the opening of a world for sites that need graphical rendering to be understood.
Google rendering: how it works and what value it has
To render web pages, Google uses a two-step or wave process designed to help the search engine better understand the content of a web page and index it effectively.
The first phase of Google’s rendering process is the analysis of a page’s raw HTML: during this phase, Google examines a page’s HTML to identify basic content and structural information, through a kind of “quick read” that allows the search engine to get a general view of the page’s content.
The second step in Google’s rendering process is the execution and analysis of the JavaScript code: in this process, which due to the complexity and resources required to execute the JavaScript can occur days or even weeks after the previous one, Google executes any JavaScript code on the page to generate and display dynamic content.
Rendering is critical for SEO because it determines how and when the site’s content is displayed and indexed by Google: if the site makes heavy use of JavaScript, it is possible that some content may not be indexed immediately during Google’s first wave of indexing because of this lag, and thus there may be a temporary reduced visibility of the pages in search results.
Even worse, of course, if content is not properly rendered, because in this case Google may not be able to “see” and thus index this content, resulting in reduced visibility of the site in search results. In addition, inefficient rendering can lead to longer loading times, which can negatively affect the user experience and, once again, the site’s ranking in search results.
Rendering according to Google: the recipe analogy
To better understand how Google handles rendering, we can think of what happens when we prepare a recipe, taking an analogy devised by the aforementioned Martin Splitt.
Google’s first wave of indexing is like reading the ingredient list of a recipe: it gives Google an overview of what the page contains. However, like reading a list of ingredients, it does not get the full picture of the finished dish.
This is where Google’s second wave of indexing comes in, which is like following the steps in the recipe to actually prepare the dish. During this second wave, Google runs JavaScript to “prepare” the page and display JavaScript-based content. However, just as preparing a recipe can take time, Google’s second wave of indexing can also take time, sometimes days or weeks.
From an SEO perspective, rendering is critical because it determines how and when site content is “served” to Google and, consequently, how and when it appears in search results. If parts of the “dish” (i.e., the website) are JavaScript-based and therefore require Google’s second wave of indexing to be “prepared,” they may not be immediately visible in search results.
To ensure that the “dish” is ready to be served as soon as Google reads the “ingredient list,” we can use techniques such as server-side rendering (SSR) or prerendering, which prepare the page in advance, generating a static version that can be easily “tasted” by Google during its first wave of indexing.
Furthermore, just as a cook would do taste tests while preparing a dish, we should regularly test the site with tools such as Google Search Console to ensure that Google is able to “taste” and index the content correctly.
Ultimately, understanding how Google “prepares” the site and how to optimize the dish for this process can make the difference between a site that is easily “tasted” and indexed by Google, and one that remains hidden in the “refrigerator.”
