
Google is deleting its links to cache? Fear not, here’s what to do
Goodbye to the Google cache. Initial rumors date back to the past few weeks, but now the official news is out: Google Search no longer shows links to web pages it has stored and will soon remove the caching feature altogether. It’s a change that marks the end of a feature that has been an integral part of users’ search experience for years and has also often been useful for debugging SEO problems. But don’t worry: there are still alternative ways to view cached copies of web pages, and SEOZoom is involved!
What is the Google cache
The Google cache is a feature that allows users to view an archived version of a web page as it appeared during the Google crawler’s previous visit. These backups, or snapshots, are available through a specific link placed next to the search result URL in classic SERP preview snippets, traditionally available under a small triangle or in a drop-down menu. Clicking on this link opens the version of the page saved the last time Google’s crawler visited it in the browser.
As Google’s crawlers explore and index the web, it regularly creates and updates these archives, thus providing a valuable resource for accessing content that may no longer be available on the original site.
In practice, it was (we have to get used to talking about it in the past tense!) a kind of digital time machine that allowed users to access earlier versions of a web page.
Discover an alternative to Google’s cache




Google’s cache feature was introduced as early as the first years after its 1998 debut and was one of many innovations that made the difference between Search and other search engines, highlighting Google’s focus on user experience and the quality of its search services.
To be sure, Google’s cache has quickly become a valued tool for both users and Web professionals because of its ability to provide access to information that might otherwise have been temporarily or permanently inaccessible.
What the cached copy is for
This feature was particularly useful in several circumstances: for example, caching offered the ability to retrieve desired information if a page was temporarily unreachable due to technical or server-side problems. Also, for SEO professionals, the cache was a valuable tool for analyzing the changes made to a page and better understanding how and when Google had last crawled the site.
In fact, Google’s cached copy was born in a different technological era, when many websites could have rather long down periods and server overloads were also more common: viewing a copy of the page previously saved by Google while scanning and indexing the web was often the only way to access the content of a temporarily down site.
How Google’s cache storage works
The Google cache was thus the result of a complex technical process involving Googlebot and Google’s other crawlers, the automated programs that scan the web to discover and analyze pages to add to Google’s index, which as we know is the database that algorithms draw on to provide search results.
When a Google crawler visited a web page, it not only analyzed its content and structure to understand what the page was about (the process known as crawling), but also created a copy of the page, which was then stored in Google’s servers, becoming a kind of “snapshot” of the page at the time it was visited by the crawler.
This snapshot is what was called Google’s “cache.”
The cache was available primarily for pages that had been indexed by Google, meaning that not all web pages ended up in the cache: only those pages that the crawlers had visited and deemed worthy of inclusion in Google’s index could have a version stored in the cache. In addition, some pages could be excluded from the cache for various reasons, such as.
- Robots.txt directives. The robots.txt file provides instructions to crawlers on which pages should or should not be indexed or cached.
- Metatag Noarchive. A specific robots meta tag in web pages that tells crawlers not to cache that page.
- Technical problems. Sometimes, technical problems or errors may prevent crawlers from properly accessing or caching a page.
- Dynamic content. Pages with highly dynamic or frequently changing content may not always be properly captured in the cache.
- Legal issues. In some cases, Google may remove the cached version of a page as a result of legal issues or removal requests.
The strategic function of Google’s cache
When it was up and running, the Google cache was an extremely useful tool because it allowed the content of a page to be seen even if the original site was no longer available or if the page itself had been modified or removed from the web. This was invaluable both for users looking for information and for SEO professionals who wanted to analyze pages from the point of view of indexing and ranking in the results.
Thus, it was not just a simple repository of web pages, but a real strategic resource for both ordinary users and web professionals. For users, the cache was a tool for immediate access to content that, for various reasons, might not be temporarily available online, such as during down periods for maintenance or due to traffic overload.
For website owners, then, the cache acts as a lifesaver in downtime situations, allowing visitors to still access content and helping to maintain some continuity in the user experience, at least partially reducing the negative impact of any service interruptions.
In addition, Google’s cache has also been a useful diagnostic tool from an SEO and digital analytics perspective, allowing visitors to see the latest version of a page that Google has indexed and to understand what elements have been taken into account by the search engine, but also to make sure that the changes made had been recognized and indexed correctly.
Google removes links to cached versions of pages
All of this then becomes web “history” because for the past few days Google has decided to remove the link to the cached copy from the SERPs and end this archiving operation as well.
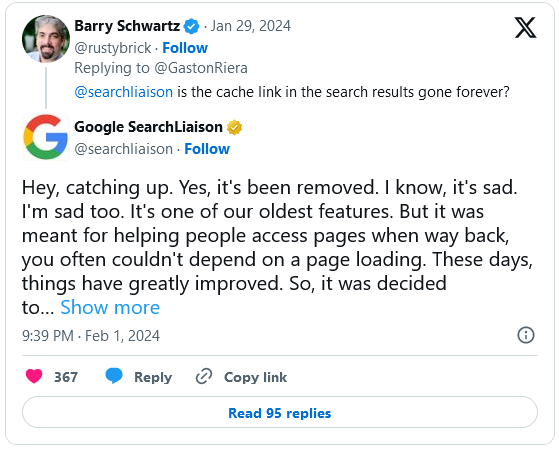
The final confirmation came from a tweet by Danny Sullivan, Search Liaison at Google, who precisely announced that the search engine had permanently removed cached linking from Google’s search result snippets as early as the end of January and would go on to divest all other related operations as well, starting with the removal of retained copies. Currently, for example, no cached links are visible in Google search results, and all Google support pages related to cached links have also been removed.
The reasons for Google’s decision
Google’s decision to remove cached links from its search results pages surprised many and marks the end of an era, with Sullivan also providing (quick) explanations for this farewell.
The critical point lies in the fact that the cache copy feature is now considered obsolete: with the vastly improved infrastructure of the Internet, professional websites are almost always available, and web page loading today suffers fewer hiccups than in the past. Thus, the use cases of the feature had greatly reduced.
As one can easily imagine, not everyone agreed with these considerations and considered them only part of the issue.
In fact, other analysts extended the considerations to more contingent and far more concrete factors: as mentioned above, the caching process was rather onerous in both technical and economic terms, and-at a time of increasing focus on cost savings, as attested to by the news of ongoing layoffs at the Mountain View group-this feature had simply become too expensive to maintain. Besides, deleting archived data will free up processing resources.
Alternatives to Google’s cache: how to save and view stored pages
With Google’s farewell to the cache, users and SEOs will no longer be able to rely on this feature to access content that is no longer available or to view older versions of a web page.
Fortunately, there are alternative ways to retrieve offline, deleted, or older version web pages.
The first method brings you back to one of the most well-known advanced search commands, namely cache: followed by the URL of the page you wish to search. By entering this command directly into Google’s search bar, you can attempt to access the most recent version of the page stored by Google, if available. In addition, you can also use another route, namely by adding the URL of a website to “https://webcache.googleusercontent.com/search?q=cache:”
However, even these search operators are expected to be discontinued by the search engine soon.
It is therefore necessary to start turning to other tools for archiving web pages, such as the Internet Archive (a non-profit digital library, active since 1996), and its Wayback Machine, which precisely preserve historical snapshots of web pages and also offer the possibility of manually adding web addresses for storage. To be precise, the “Wayback Machine” allows users to browse the history of almost any web page and view how they appeared at past dates, completely free of charge, as well as restore missing pages, read digitized books, share archived links on social media, and more (with registered accounts or even without).
It was Sullivan himself who cited this system as “the best alternative to Google’s cache,” and indeed even opened to the possibility of seeing Google add links to the Wayback Machine to allow users to access archived versions of those pages. Specifically, the Search Liaison hopes that it will be possible to add a link to the Internet Archive within About This Result so that people can easily see how a page has changed over time while also contributing to the information literacy goal of this Google feature.
Back to alternatives to Google caching, it is good to know that there are several plugins and third-party services that allow you to create personal archives of web pages, ensuring that content can be saved and accessed in the future.


Try our Monitored pages
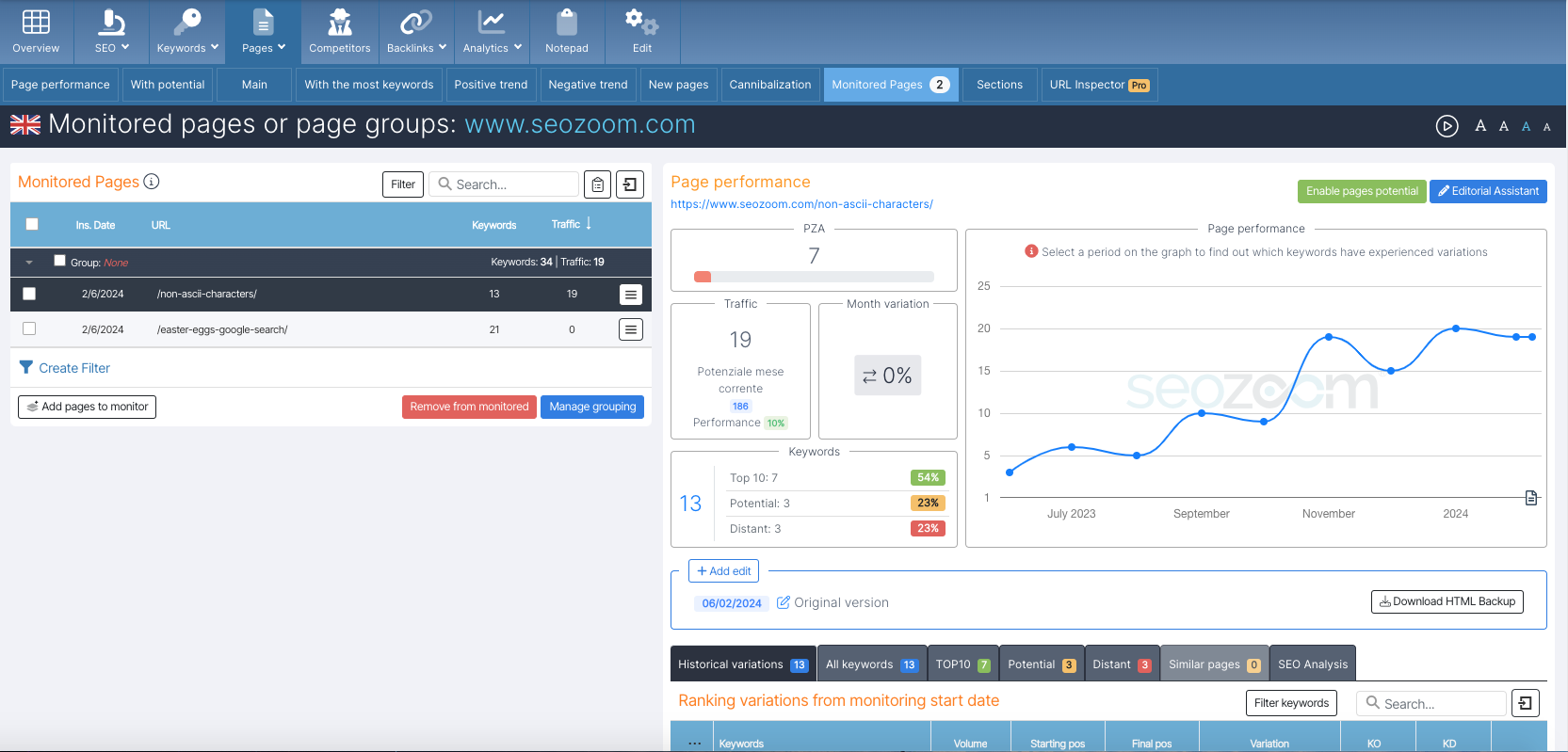
And then there is SEOZoom! We should not forget, in fact, that our software provides users with the “Monitored Pages” section that allows you to manually add specific pages or project site paths to be kept under in-depth scrutiny.
In addition to the basic functionality – analyzing page performance in detail and checking the most important data for your strategies over time – within this tool you can set it to save the page at the “current state it is in” at the time of insertion and also download the HTML version of this save. Basically, you can use SEOZoom to make a kind of cache copy of the page, also adding notes to indicate the changes you have made and later find out the outcomes and concrete results of these interventions. This is an interesting opportunity to overcome Google’s decision problem, which is certainly more oriented to the SEO aspect of page caching and clearly related to the number of projects and pages that are actually available to one’s account.
Limiting then to Google’s scan verification, it is clear that all users with a verified property can use the Search Console’s URL Inspection tool to see what Google’s crawlers see when they view pages on their sites. Again, this is only part of the options originally allowed by the cache copy, but now the die is cast and all we have to do is adapt!
