
Cache for a website: a thorough guide
A temporary repository of resources that are quickly downloaded and retrieved with each request-essentially, we can define the cache and caching activity in this way, i.e., the process of storing certain resources locally so that they can be reused without the need for a full round-trip request pass to the server. Caching can prove to be a crucial element in the optimal functioning of a website and its performance, and in this in-depth guide we will explore the concept of caching, its purpose, how to manage it, and common problems associated with it.
What is the cache
Caching is a process of temporarily storing copies of files, images, Web pages, and other elements in an easily accessible location to reduce the loading time when a user visits a Web site. Resources such as HTML, CSS, images and JavaScript can all be cached.
The term “cache” comes from French and means “to hide” or “to store.” In the context of websites, cache refers more specifically to different types of temporary storage, such as browser cache, server cache, or Content Delivery Network (CDN) cache.Each type of cache has a specific role in speeding up page loading and improving the user experience.
Regardless of the type, in fact, the cache remains a temporary storage mechanism useful for storing data that is frequently used, with the aim of reducing the time needed to access it. Cached pages are provided as static HTML versions to avoid potentially time-consuming queries to the database: publishing the most recent version of a page might, for example, require accessing database information, and this takes longer than publishing an already archived (cached) version of the page.
And so, specifically, a website’s cache is used to store a copy of web pages and their content in order to decrease loading time and, as mentioned, improve the user experience.
How the caching mechanism works: the three main modes
But suboptimal caching does not only mean a bad user experience, because it also means worsening the dialogue with Google crawlers, precisely because of the specifics of this process. To better understand, we need to analyze the 3 main types of caching, their characteristics and the ways they affect each other.
- Server-side caching
Server-side caching works by temporarily storing responses to dynamically generated requests and content on the server’s own infrastructure rather than on a client-side device. This type of caching can be useful if we have a site that publishes content that changes frequently, but can be equally stored temporarily to reduce page load time.
The advantage is that we have control over the storage settings, and in particular we can define different cache times for different files (and file types) on the site, evaluating the user’s need to see the latest version of that file. For example, front-page HTML content should probably be cached more often than the background image or style sheet.
The frequency of caching depends on the type of site in question: a news site might require a cache update with each user visit, and everything must be evaluated by examining the market niche, the content of the site, and even the similar actions of competitors.
Cache management is regulated by assigning an expiration label, which allows the browser to know how long an item can be retained and reused, and when to request it again from the server. Setting cache duration correctly will speed up load times for users-which is why Google suggests configuring a one-year validity period for most static resources. By adopting advanced version control techniques for resources, we will also be able to use longer cache durations: if the name of a file changes, the server will automatically request the new file from the server without drawing on the previously cached version. If we do not set a duration for the cache, on the other hand, the server will intend that it is necessary to retrieve the resource again each time, possibly resulting in a cache miss. This can often cause significantly longer load times.
The typical process of the server-side caching mechanism can be summarized in these key steps:
- Initial request. A user visits a dynamically generated Web page; the server receives the request and computes the response based on the dynamic content and request parameters.
- Caching. The server stores the generated response in the cache and sets a validity interval.
- Subsequent requests. If another user requests the same web page within the validity time interval, the server will directly provide the cached copy instead of recalculating the response again.
- Validity check. Once the validity time interval has expired, the cache is declared invalid and the server will have to regenerate the response and refresh the cache when it receives a new request.
This management of static code, content and queries can be supported by using a CDN, which uses a network of servers distributed around the world to dynamically return data based on the user’s geographic proximity. This feature allows sites to operate efficiently in demanding situations and deliver content to users based on location and capacity in real time.
- Browser Cache
Browser caching occurs at the individual visitor level-we do not have complete control over it, but we can influence it through the server’s caching settings, which tell the browser whether or not it should retrieve the latest version of each resource.
In practice, temporary storage of site information is hosted in the visitor’s device cache for retrieval at a later time; the returning visitor can also manually manage the cached data and clear the internal cache if necessary. This allows serving a responsive browsing experience while limiting server load, and is useful for large, complex sites or e-commerce pages with significant return audiences.
Browsers such as Google Chrome and Firefox typically cache so-called static resources (images, CSS), those that do not change too often from one visit to the next and therefore can be loaded much faster, since they do not have to be downloaded again from the Web.
When a user visits a Web page for the first time, the browser requests from the server the resources needed to display the page, such as HTML files, CSS, JavaScript, images, and other media; upon receiving these resources, the browser may store them in the local cache (browser cache) in the user’s device.
Although it is not possible to control how a user sets his or her browser cache (if he or she wishes, he or she could even perform a full refresh each time), browser caching is still very important, as this is how the browser remembers and stores visited websites in their local memory, helping the site load faster. As site owners, we can also dictate what information the client browser cache retains on a page-by-page basis, and we can also choose to clear our cache to get rid of outdated or “old” material – something that should always be done after a site redesign or after the completion of a significant update.
- Google Cache
We also focus on a third form of caching, the one performed by search engines such as Google, which store a backup version of a web page that can be provided to a user in lieu of the most recent version of that page. When a search engine, such as Google, indexes a page, it usually creates a cached version that users can view if the original website is unreachable or slow.
The Google cache is thus a snapshot of the page content and is captured when Google last crawled the website page.We have no precise information on how this storage works, but experiments suggest that Google’s crawler stores its visits to the site in a kind of “virtual” browser cache. Each time it crawls the site, it seems to use what is already in the browser’s virtual cache as a baseline, which allows it to crawl progressively more each time.
Google’s caching capabilities have a number of advantages, most notably:
- Search results: it allows search session results to be presented quickly to users, as it allows a cached copy of the web page to be displayed without having to draw directly from the original URL.
- Change tracking: the Google cache facilitates the study and analysis of changes made to web pages over time, so as to simplify analysis and evaluations on SEO optimizations.
- Content availability: if a website is temporarily offline or inaccessible, Google’s cache still allows users to view its last indexed state. Therefore, users can access the content even if the original server is temporarily unreachable.
With respect to the latter point, by using the advanced search operator cache:website.com/page (to be replaced with the exact URL) we can find out the last time a site or page was cached, as well as view precisely the last static copy in Google’s virtual archive. We can also reach the cached copy of a web page from Google’s SERP, by clicking on the three vertical dots that – in the latest versions – lead to the “About this result” feature, which precisely also includes a “cache” button that makes us display the cached version of the web page.
It is important to note, however, that if the server-side caching settings instruct users to retrieve the latest version of each resource on each visit, Google’s crawler (which is a virtual user) will also not be able to rely on previous scans and thus may scan a smaller part of the website; if the server settings then impose a refresh on each visit, we may run into ranking problems.
Site cache: what it is used for and how to manage it
A separate discussion is reserved for site caching, that is, client-side controlled caching, which allows visitors to access the site and its pages via Google Cache. This feature proves useful for site owners who experience problems with site traffic management infrastructure difficulties.
In short, site caching provides a “backup” of content that allows returning visitors to view resources that may be temporarily unavailable or inaccessible if and when site elements cease to function. The display of a cached version of a Web site or page is controlled by viewers in the front-end of the site; this back-end configuration allows owners to determine what data to cache for return and how long it should be retained.
Cache function options can be set on a page-by-page basis, allowing site owners to provide a responsive site that loads quickly and performs well. In this way, sites can optimize caching even if they offer a combination of regularly updated content, long-standing materials, or complex elements that cannot be stored.
Site caching has several purposes, and in particular it can serve to:
- Improve performance: Caching reduces the loading time of web pages, as it allows the browser to quickly retrieve stored data instead of having to request it from the server again.
- Reduce load on the server: A portion of the requests are fulfilled by the cache, so the server is less stressed, improving its efficiency and stability.
- Save bandwidth: Caching reduces the amount of data that must be downloaded by site visitors, decreasing bandwidth costs and increasing browsing speed.
We can use several methods and tools to manage site cache, such as:
- Plugins and modules: Numerous plugins and modules are available for content management systems (CMS) such as WordPress, Drupal, and Joomla, which make it easy to configure and optimize the site cache.
- Server configuration: At the server level, tools such as Varnish or Nginx can be used to implement more advanced and customized caching.
- Browser Cache: Caching policies can be set through the use of HTTP headers, which allow you to control how long and how visitors’ browsers are cached.
How to prevent caching
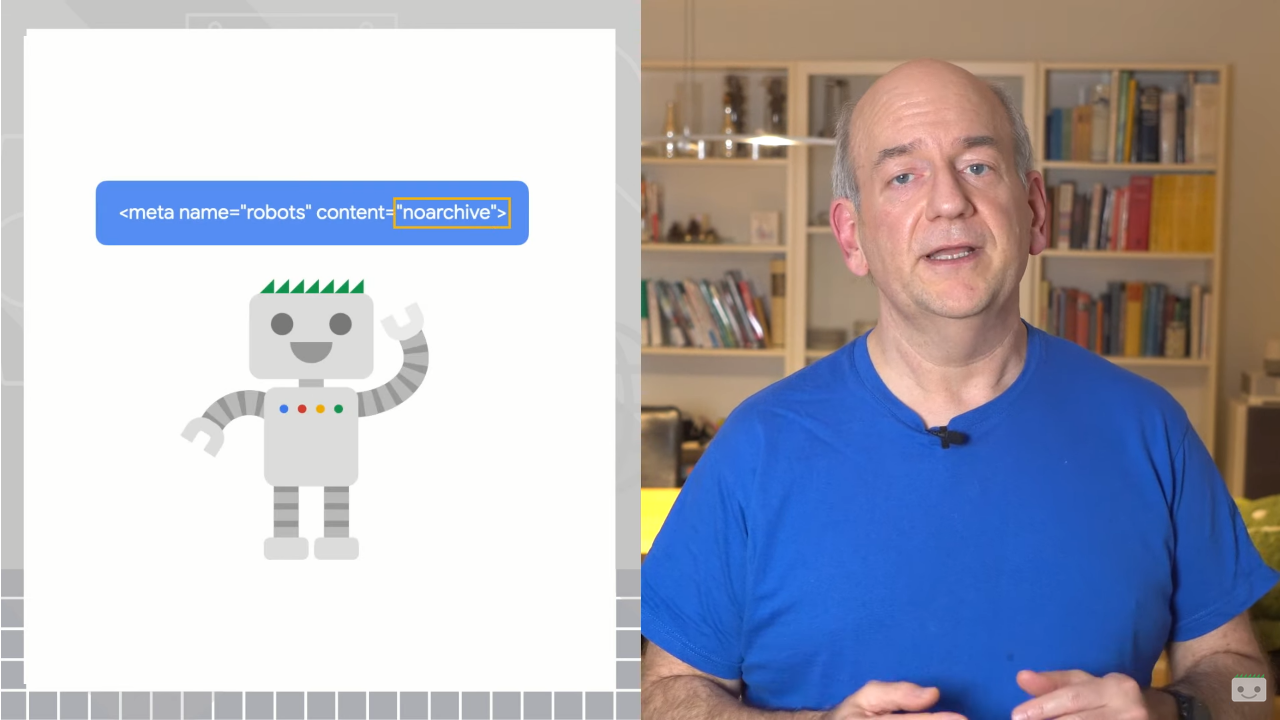
If we do not want the website to be cached or appear in archive.org – a possible eventuality, for example, if we have dynamic pages with constantly evolving content-we can use the following metatags, which, inserted in the <head> tag of the HTML page, tell search engines how to handle temporary storage (caching) and archiving of web pages in their index.
- content=”noarchive”
- content=”no-cache”
Specifically, content=”noarchive” specifies to search engine crawlers not to save a cached copy of web pages. As mentioned, when Google indexes a page it usually creates a cached version of the page, which users can view if the original website is unreachable or slow: by using the content=”noarchive” tag we prevent the search engine from creating and displaying this cached version on search result pages.
The content=”no-cache” metatag tells search engines and browsers that the page should not be stored in the browser cache: this means that whenever a user visits the page, the browser will have to load it directly from the server instead of using the version stored in the local cache. This could be useful for pages with dynamic or sensitive content that changes frequently and requires updating in real time. Unlike the previous case, the “no-cache” tag is placed in the <head> tag of the HTML page, but within a http-equiv type meta.
It is important to note that the content=”no-cache” metatag is not always sufficient to prevent browser caching, as some browsers may ignore it. Therefore, it is advisable to also manage the cache by sending HTTP “Cache-Control” headers from the web server.
The importance of optimal cache management
Properly managing a website’s cache is crucial for a variety of reasons, starting with a potential benefit to page performance and the consequent improvement in UX.
When a user first visits a Web site, his or her browser saves selected site elements in its internal cache: this feature allows a variety of materials to be stored on the visitor’s computer, which can be quickly retrieved from memory when he or she returns to a Web site instead of extracting data from repeated downloads of content. Proper caching helps optimize site bandwidth utilization, reduce server load, and manage operational costs, and this also benefits visitors because it improves page responsiveness, allowing access to content that may be unavailable due to interruptions, and improving the overall user experience to encourage return visits.
There are three positive aspects in particular that we can highlight:
- Speed of page loading: a well-managed cache reduces the time it takes to load site pages, thus improving the user experience and positively affecting the site’s ability to convert visitors into buyers or leads, decreasing the abandonment rate.
- Resource savings: caching reduces the load on the server, as cached resources are delivered directly to the user without the need to obtain data from the server again. This contributes to greater efficiency and optimized resource utilization.
- Improved SEO: page loading speed could go some way toward improving search engine rankings and thus SEO. With good cache management, the site will be indexed faster by search engines and could benefit from a better position in search results, operating with optimal efficiency.
In summary, then, caching is an aspect that can have a bearing on the SEO health of the site, and without a properly configured cache at the server level, the website may even have difficulty functioning smoothly.
Common problems with site cache
Although caching is an essential element in improving a website’s performance, it can sometimes cause problems, which affect the user experience or compromise storage itself. The most common are:
- Outdated content: When the cache is not updated properly, visitors may see outdated versions of web pages, causing possible inconsistencies and usability problems.
- Compatibility problems: Some plugins or themes may not be compatible with cache settings, causing malfunctions or visual errors.
- Difficulty in troubleshooting: If there are problems with the site, caching may make it more difficult to identify and resolve the cause, as you may need to clear the cache to see the effects of the changes you make.
On the technical side, however, these practical problems prove frequent:
- Cache duration too short or absent: a cache expiration that is too short or the lack of a default expiration can cause poor cache utilization, resulting in increased load times and load on the server.
- Excessively long cache duration: setting too long a cache duration for dynamic and frequently updated content can lead to outdated versions of pages being displayed to visitors, causing content update and usability problems. A tip for managing duration appropriately is to check the strategy of better positioned competitors and “take a cue” for our own settings.
- Lack of version control of resources: without proper version control of static resources, visitors may continue to use old cached versions even when updated versions of resources, such as CSS, JavaScript, and images, are available. Likewise, it is important to verify that the cache has stored the correct page, especially among Google search results.
- Use of non-canonical URLs: using different URLs for the same content can generate duplicate caches and waste of resources, as the browser or server may store multiple copies of the same content.
- Failure to compress files: failure to compress resources such as CSS files, JavaScript and images can increase load times and bandwidth used, negating the benefits of caching.
- Failure to configure the server cache correctly: misconfiguring the server cache for a dynamic application can cause errors, such as displaying outdated or inconsistent content.
- Failure to optimize for mobile devices: if the cache is not optimized for mobile devices, users may experience long loading times and a compromised user experience on smartphones and tablets.
- Failure to configure CDN caching: Failure to configure or inadequate use of a CDN network could adversely affect the distribution and optimization of static resources.
To manage these problems, it is important to properly monitor and configure the cache, ensuring that it is updated regularly and that it is compatible with other components of the site; it is advisable to thoroughly test changes made to the site and cache settings to ensure that they do not cause problems to the user experience or site performance.
How to fix any problems with the Google cache
While efficient cache management can potentially lend a hand to efforts to gain organic visibility, the downside is the traffic and ranking losses that can result from incorrect settings.
When we encounter problems with Google’s cache, we can take action with some checks and fixes:
- Check of the canonical tag and its correct usage.
- Check of the sitemap and, if necessary, generation of a new sitemap.
- Check of Google’s Search Console for any warnings or messages.
- GSC URL Inspection tool check.
- SEO audit for a diagnostic, using tools such as Screaming Frog or SEOZoom’s Spider.
- Check server caching settings.
Google and caching, SEO clarifications
Also speaking on the topic of caching recently was John Mueller, who devoted an episode of his AskGooglebot on YouTube pills to answering a community doubt: namely, “Does Google have to cache a page in order for it to appear in Search,” and therefore is it essential to store cached copy in order to appear in Search?
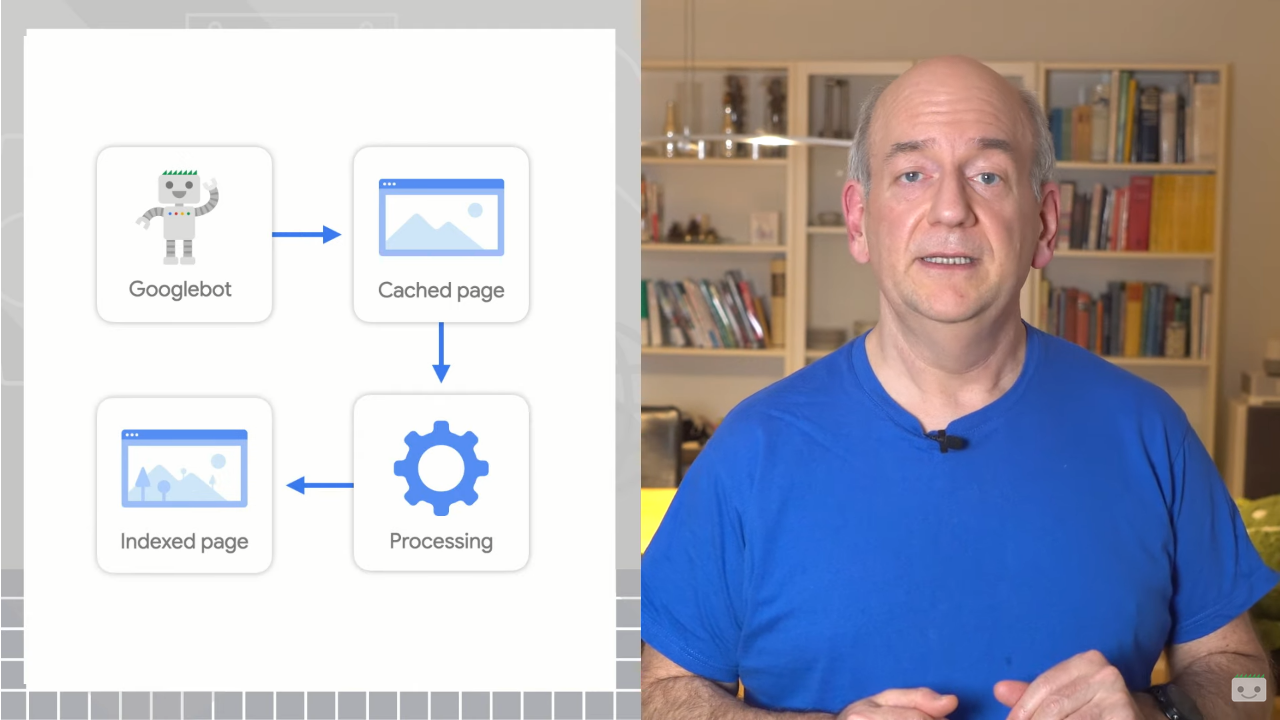
The Search Advocate’s short answer is “no,” pages do not have to be cached to appear in Google Search, but the details are actually a bit more complicated.
Cached pages are somewhat separate from indexing and don’t always reflect what is indexed, Mueller says, but they are often the same, however, and that can actually create some confusion.
Some pages are not cached as a result of system design choices in Google’s infrastructure, and also (as seen) we users can also decide that our pages are not cached, using the robots “noarchive” directive.
For JavaScript-based pages, the entire page may not show up in the cache because of security policies in browsers, since the cached page is loaded from a Google domain.
So, in short, just because a page is not cached does not mean that there is a problem with indexing that page. And, in general, caching is not necessary for Search.
