
Semantic Search, the key to modern SEO
It has been talked about for more than fifteen years and, as revealed by the late Bill Slawski, Google’s first patents in this direction date back as far as 1999. However, it is only in recent times that semantic search has really become an everyday reality, thanks to developments in technology and applications of Artificial Intelligence and machine learning. Somehow, if SEO is still the art and science of optimizing online content to improve visibility in search engines, a lot also depends on this “subcategory” that has prompted search engines to focus on deeper understanding of the meaning behind keywords and search phrases, rather than exclusively on exact keyword matching. Let’s find out what exactly is meant by semantic search and what kind of impact it has on SEO.
What is semantic search
Semantic search is the process that search engines use to try to understand the intent and contextual meaning of the search query, with the goal of delivering results that are accurate, relevant, and relevant-that is, that match what the user had in mind. In other words, semantic search aims to b a person is searching for that particular string of terms in the query and what he or she intends to do with the information obtained.
To achieve this goal, search engines analyze various elements, such as the search context, the user’s geographic location, word variation, synonyms, generalized and specialized queries, concept matching, natural language queries, but also the relationship between words and understanding the underlying entities. This very concept, entities, is one of the fulcrums for Google’s semantic search: in a nutshell, the term describes the essence or identity of a concrete or abstract object; it is something uniquely identifiable and therefore uniquely meaningful.
Underlying the evolution of semantic search are a number of evaluations, but most importantly, consideration of the fact that search queries can be ambiguous in nature, as can the words themselves; moreover, people speak and ask for things in different ways, languages, and tones, which cannot (any longer) be unified with standard SERPs that consider only the old exact match.
It is important to note that we should not confuse semantic search with latent semantic indexing (LSI) or what some might call semantically related keywords: LSIs can help provide context about the topic of the content (and potentially help match search intent), but semantic search is much more than that (and LSIs do not help ranking, as reiterated in various circumstances by Google).
A guide to semantic SEO
Semantic SEO refers to the use of SEO techniques that focus on the meaning and user intent behind a given search query, rather than the exact match of keywords. This approach is based on understanding the context in which keywords are used, rather than simply their presence in a piece of content.
For example, if a user searches for “apple,” he or she might be referring to the fruit, the technology company, or a number of other things-a search engine using semantic SEO will try to understand the user’s intent behind this search, based on a number of factors such as the user’s location, previous searches, and other contextual data.
In a nutshell, semantic SEO enables search engines to deliver more relevant and useful results, improving the user experience and increasing the likelihood that the user will find exactly what they are looking for.
What semantic means in the context of search
The expression “semantic search” refers to the branch of linguistics called precisely semantics, which studies the meaning of words and phrases (of language in general) in certain contexts and the relationship between those words.
Applied to Web search, semantics refers to the connection between a search query, the words related to it, and the content of Web site pages; all of these elements combined help search engines understand what search queries mean beyond a simple literal translation, so as to provide results that are actually related to the context.
Meaning, however, is not synonymous with intent, and so semantic search cannot be simplistically understood as an interpretation of search intent: as Olaf Kopp points out, at its essence, semantic search is about recognizing the meaning of search queries and content based on the entities present. This ties in, precisely, with the definition of semantics as the “theory of meaning“, and in this context “meaning” is something different from search intent – an expression that, as we know, describes why a person performed a search and, simultaneously, also what he or she expects from the search results-that can help to recognize intent and becomes a kind of additional benefit of semantic search.
Trying to simplify, let’s think about our daily experience: when people talk to each other, they understand (often automatically and without caring) more than just words, because they understand context, nonverbal cues (such as facial expressions or voice nuances), and much more. This all happens naturally, so it is not easy to take a step back to describe what is being communicated without the help of all the “beyond words” signals.
How semantic search engines work
With search engines, this means moving from merely identifying the query to algorithms understanding what is behind it: for example, if we search for “wedding dresses,” related words might include “wedding,” “cake,” “bride,” and “dream,” while if we search only for “dresses,” related words might be “elegant,” “casual,” “long,” and so on.
Therefore, a semantic search engine considers the semantic context of search queries and content to better understand their meaning, while also being able to analyze and evaluate the relationships between entities to return search results. This represents a clear evolution from previous purely keyword-based search systems, which instead function by searching only for a match between keywords and text.
The most modern semantic algorithms manage to create a mathematical model that can identify a “relevance score of a given document for any user’s search query”, as our own Ivano Di Biasi used to say a few years ago; such algorithms are used to search in documents concerning a specific field and manage to provide vertical search functionality on a field, even if it has a small number of topics/topics.
Increasingly, today the search engine analyzes the semantic field of each word, attempting to identify all other words relevant with the query: this is what is called semantic field expansion, which allows the algorithm to recognize that singular and plural are not two different queries (apart from special exceptions, related to intents) and that some verbs have the same meaning.
Semantic search also allows search engines to distinguish between different entities (people, places, and things) and interpret searcher intent based on a variety of factors, including user search history, geographic location, global search history, and spelling variations. All of this helps Google and other search engines provide a better experience for their users by delivering quality and giving preference to relevant content results.
The evolution of search engines
This process became inevitable to accommodate the growing needs of users, who were dissatisfied with the type of answers previously provided by the various SERPs built on non-semantic models.
Previously, standard search engines worked by focusing on keywords: that is, their crawling started from the analysis of the input provided by the user in the search bar (the query, consisting of one or more keywords), to search for its specific occurrence within the documents in the index and, based on a series of ranking factors (including, at the time, the frequency with which the query was repeated within the document), provide in response a SERP with results ordered precisely according to particular criteria.
All listed documents – web pages – thus had one feature in common: they contained within them the keyword or string given by the user in the search query, preferably in a format perfectly identical to the wording of the input. This is what is called exact matching, or literal coincidence with the keyword (however ungrammatical or incorrect).
More importantly, in classical search each word is independent of all others, because algorithms are unable to understand elements such as synonyms, gender forms, variation of singular or plural of the same word, and often exclude some terms from the search (the classic stop-words, such as articles or prepositions). Thus, even essentially identical (according to current sensitivities) queries such as “how to make websites,” “how to make a website,” or “how to make websites” produced completely different SERPs, evaluated on the basis of occurrences of the exact string of terms within the content (and the algorithm’s other ranking criteria).
A mapping of entities and concepts
Underlying it is always the same problem that also drives the broad core updates and other interventions: Google, along with the other search engines, is trying to (and often struggling to) understand what its users want, without actually seeing or hearing them, with the goal of satisfying searches with more accurate results. And this is precisely where semantic search comes in, linking search intent with content context to provide the most relevant and useful results, making any topic (or search query) easy for a machine to understand.
Without going into too much technical detail (for which semantic analysis professionals would be needed), underlying semantic search for engines are two main concepts, as Ann Smarty explains:
- Semantic mapping, which means exploring the connections between any word/phrase and a set of related words or concepts.
- Semantic coding, which is using coding to better explain to Google what types of information can be found on each page.
More specifically, semantic mapping is about visualizing the relationships between concepts and entities (as well as the relationships between related concepts and entities), and this image gives us an understanding of the graphical representation of the model as envisioned by Ramanathan Guha of Google, the future creator of the Schema project.

This model helps Google better understand any related query and provides useful search cues (such as knowledge graph, quick answers, and others). Semantic analysis also helps Google better serve voice search users by providing them with immediate answers based on their generic understanding of a topic.
New search engine answers and semantic coding
Great support for the evolution of semantic search engines then comes from the Schema.org project, created in 2011, which offered site owners even more ways to convey the meaning of a document (and its different parts) to a machine. From then on, the site was able to directly communicate to a search crawler information about the author of the page, the type of content (article, FAQ, review and other similar pages) and its purpose (fact-checking, contact details and more).
It is still Smarty who says very emphatically that “semantic markup exists for a reason, the desire to communicate,” because we want to explain the purpose and structure of our content to a search engine.
With the help of semantic markup, Google is able to identify and use key information from a page; in return, so to speak, web publishers get “rich snippets“, or more detailed search listings than those that do not use semantics, and better understanding of the resource.
In fact, the idea behind using code to express meaning (not just presentation) goes back long before the schema.org project was launched, and for years we have been able to use so-called semantic HTML to communicate the meaning of content, and in particular the H1-H6 headings that describe the main topics of a document and the other HTML tags, which help all kinds of machines better understand and convey the information they find on a web page (and are in fact also called semantic tags because they add meaning to a document).
What is semantic SEO
How and how much does all this impact search engine optimization work and, therefore, what is semantic SEO? First of all, we have to remember that SEO is and remains essentially a series of interventions aimed at better explaining the purpose and structure of our content to a search engine (as well as making it easy for the user to navigate and understand, accompanying them to execute the purpose they had in mind), but today this is enriched with additional levels of analysis, to understand people’s intent and behavior, as well as the (semantic) context behind textual expressions and words.
We can therefore say that we are fully within the era of semantic SEO, since, to quote Slawski again, Web search has evolved to focus more on displaying results that find things instead of strings or matching keywords within queries with keywords in documents on the Web.
The major search engines – Google, Bing, Yahoo and Yandex, among others – all follow schema.org structured data markup, which can be used to display multimedia results in search results. This is (also) what makes semantic search visible: today in SERPs we see semantic SEO results such as featured snippets, multimedia results, structured results, knowledge panels, synonym substitution, and special entity query processing. In addition, semantic SEO also involves the inclusion of entity facts or attributes on pages, and we can also identify the entity class, link to information about that entity and information that people should know about those entities-what powers E-A-T evaluation for Google, wanting to simplify.
From a practical perspective, semantic SEO is the process of using related topics and entities to help search engines better understand site content, and it helps provide search engines with more context about a given page, making the content more complete. A semantic SEO search results page can include:
- Knowledge panels.
- Entity-filled search carousels.
- Featured snippets that can answer questions about the entities in a query.
- Related questions (boxes of “People also ask” questions that might be similar to the answers in the featured snippet).
- Related entities
and more.
How to optimize content for semantic SEO
Semantic SEO as a discipline has become increasingly popular over the past few years, although predominantly the study and optimizations have been more about copywriting, now increasingly understood as “strategic copy” in a holistic view that also brings together broader on-page interventions.
Indeed, semantic SEO discourses often include semantic optimization of content, but also the use of structured data and the structure of semantic topical worlds, and basically “it makes sense to show Google that you completely cover certain topics with your content and, therefore, demonstrate competence,” as Kopp summarizes further.
In addition, some of Mountain View’s patents deal with the comparison of internal document knowledge graphs with the Google Knowledge Graph, and the theory that seems to underlie this is that a high level of correspondence between the entities used in a text and the relationship structures of the main entity in Google’s semantic database leads to better rankings. This would also seem logical, but after all, currently keyword-based optimization does not differ significantly from entity-based content optimization.
At the same time, the expert argues that the structure of topical worlds also makes sense, although it must be said that, in times of passage ranking, we cannot overlook aspects such as the actual level of subdivision of a topic into various subtopics and the topic management itself (i.e., whether separate content is produced for each subtopic or whether, on the contrary, only global content is created).
Similarly, today structured data can help Google understand semantic relationships, but only until the search engine no longer needs it-and this will happen soon, Kopp himself predicts, because “Google is so good at machine learning that it uses structured data to train algorithms faster.”
It is therefore only a matter of time before Google no longer needs structured data, while the talk about “relationships” and the global view of entities such as publishers and authors is different. Off-page signals play more of a role here than on-page signals: based on the relationships between authoritative and credible entities, Google wants to determine which domains and authors are the best sources of quality for a topic according to E-A-T, and in particular to understand
- Who is related to whom.
- Who recommends whom.
- Who frequents whom.
Google links and co-occurrences can be used as proximity factors between authoritative entities, and semantic SEO should also consider their optimization.
Speaking of co-occurrences, the author continues, it is also good to consider the functioning of NLP (Natural Language Processing or natural language processing) in content optimization: Google uses NPL to identify entities and their context, through grammatical structures of phrases, triples (expressions formed by subject->predicate->object) and tuples (elements of a relation with attributes in a relational database) composed of nouns and verbs.
For this reason, even in semantic SEO we should pay attention to a simple grammatical structure of sentences, and thus use short sentences, without personal pronouns and without nesting: in this way we render a service in terms of readability to users and search engines.
Moving on to the keyword research phase, however, when we study keywords for inclusion in content, we should not fixate on a single term, but analyze and create so-called “keyword clusters“, or groups of related keywords, that are directly related to semantic research, because they ensure that our content covers a wider range of the topic-and, potentially, can position broaden the ranking, increasing the number of keywords per page recognized by Google as useful for the context and user need.
The idea is that using such terms in the copy helps place the content in the focus identified by Google’s semantic model, which then immediately understands that our document is in line with the searcher’s intent.
Goodbye to the old SEO
This new process of keyword research, which we summarized long ago in the phrase “there is no keyword” should be the standard of SEO activity by now and marks the big conceptual difference in today’s work from that of the past.
Until a decade ago (but there are still those who continued…. ) SEOs all over the world followed a relatively similar process: in the first stage, they would perform keyword research to find the potentially most desirable term and other related words; next, they would (forcibly or even randomly) insert those keywords into the text of a page as many times as possible, and work to bring as many backlinks as possible to that URL, from any kind of referring site; finally, they would wait for the ranking, which could even be positive-at least until the introduction of the Panda and Penguin algorithms.
The history of semantic search
In short, what we are seeing today is not a sudden revolution, but one of the stages of a process that started many years ago and had to somehow “wait” for the appropriate technological developments.
Suffice it to say that as early as 2001 the inventor of the Web, Tim Berners-Lee, published a review of his original vision of the Web and began writing about the Semantic Web, with an article hosted in Scientific American titled precisely “The Semantic Web“, in which he said that “the Semantic Web is not a separate Web, but an extension of the current one, in which information is given a well-defined meaning, enabling computers and people to work better in cooperation.”
Semantic Search and Google
But when did Google start working on semantic SEO? According to Bill Slawski, the first attempts date back to 1999 (a year after the PageRank algorithm was patented), when Sergy Brin filed a provisional patent for an algorithm called “Dual Iterative Pattern Relation Expansion,” which is the first step toward the next evolution.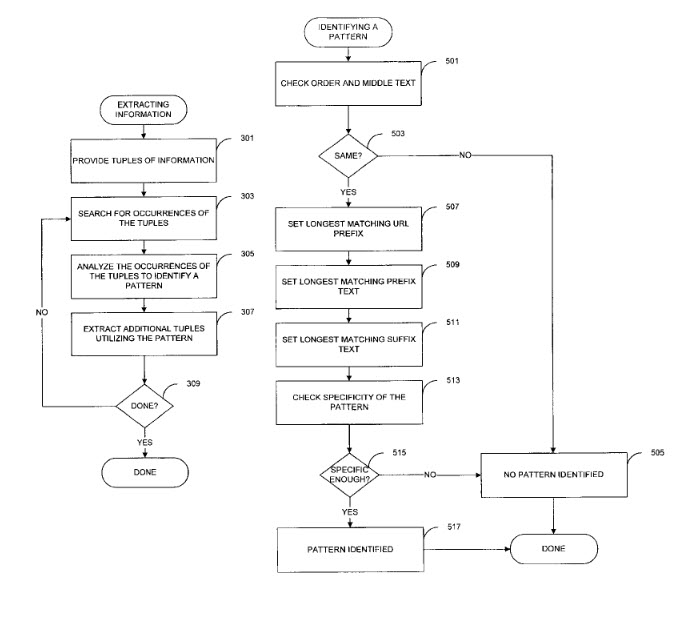
Understanding semantic SEO also means knowing Google’s technologies and approaches to extracting entity information from the Web, expressed visually by knowledge graphs that are built using that technology.
Indeed, it was the introduction of the Knowledge Graph in 2012 that began to concretize Google’s commitment to a new semantic approach to search, followed the following year by the fundamental update of its ranking algorithm, known as Hummingbird: all other major innovations thereafter, such as RankBrain, E-A-T, BERT, and MUM, directly or indirectly support the goal of becoming a fully semantic search engine. And today, by introducing natural language processing (NLP) into search, Google is moving at an exponential rate toward this goal.
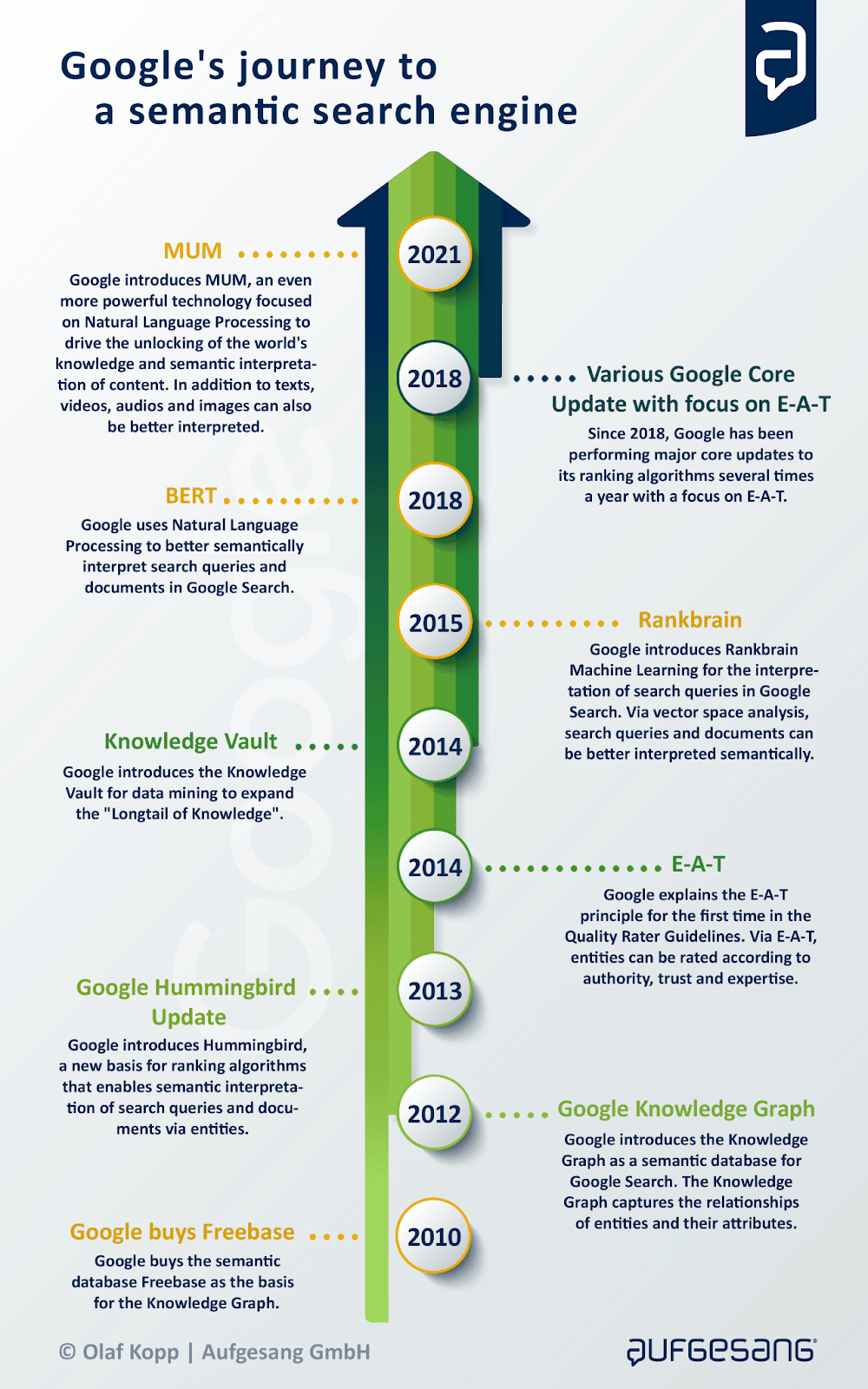
Hummingbird is the starting signal of Google’s evolution into a semantic search engine, because prior to 2013 Google was primarily concerned with matching keywords to ranking documents, and was unable to recognize the meaning of a search query or content.
Hummingbird basically replaced most of the existing ranking algorithms and was, as Kopp puts it, “the biggest change Google ever made to search query processing and ranking, affecting more than 90 percent of all searches back in 2013.” With this update, Google was immediately able to include registered entities in the Knowledge Graph for query processing, ranking, and SERP output.
The role of the Knowledge Graph in Google’s semantic search.
Entity-based ranking also requires entity-based indexing, and the tool used by Google is the aforementioned Knowledge Graph, which is precisely Google’s index of entities and takes into account the relationships between them.
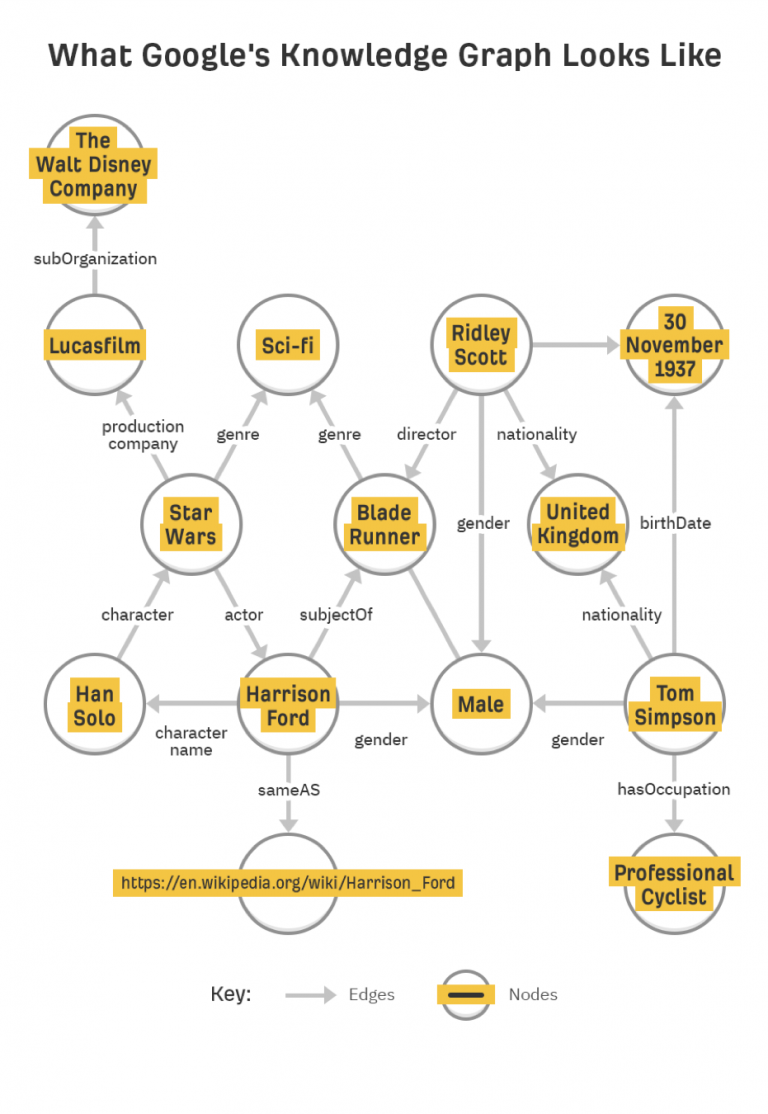
Classical indexes are organized in tabular form and, therefore, do not allow for mapping the relationships between datasets: in contrast, the Knowledge Graph is a semantic database in which information is structured in such a way as to create knowledge from information, and here entities are nodes related to each other by edges, endowed with attributes and other information, and placed in thematic contexts or ontologies.
Entities are the central organizing element of semantic databases, such as Google’s Knowledge Graph; in addition to the relationships between entities, Google uses data mining to gather attributes and other information about entities and organize around them.

The sources, attributes, and information Google considers for an entity vary depending on the type of entity: simplifying, the sources of a person entity are different from those of an event or organization entity, and this affects the information displayed in a knowledge panel in the SERP.
The structure of an entity-based index makes it possible to answer queries that search for a topic or entity not mentioned in the query.
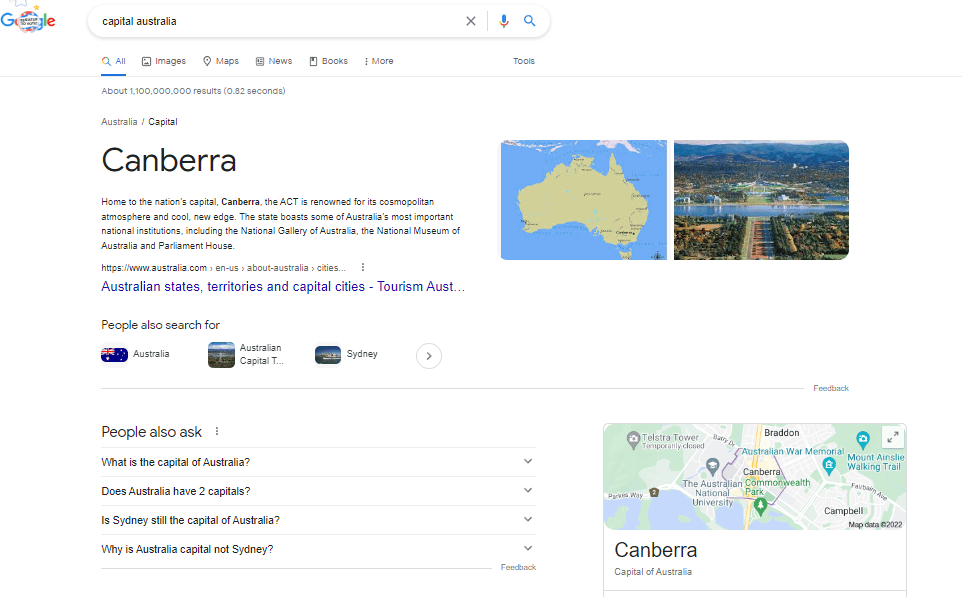
In this example, “Australia” and “Canberra” are the entities, and the value “capital” describes the nature of the relationship. A keyword-based search engine could not have provided this answer.
Underlying a Google Knowledge Graph are three levels:
- Entity Catalog. Stores all entities that have been identified over time.
- Knowledge repository. Entities are brought together in a knowledge repository with information or attributes from various sources. It mainly involves joining and storing descriptions and creating semantic classes or groups in the form of entity types. Google generates data through the Knowledge Vault, where it operates data mining from unstructured sources.
- Knowledge Graph. Entities are linked to attributes and relationships are established between them.
Google can use different sources to identify entities and the information associated with them, as also shown in the explanatory image created by Kopp himself.
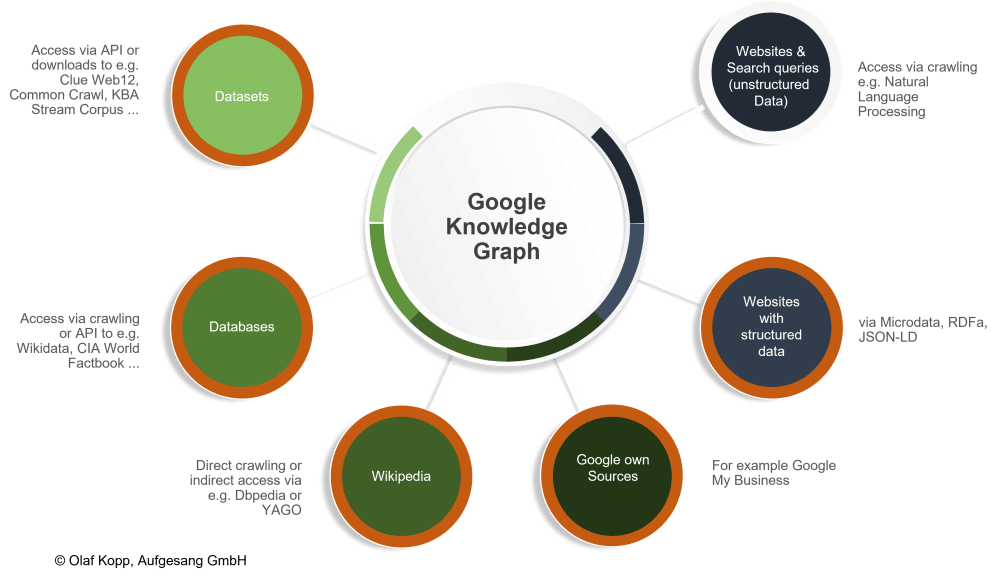
It should be understood, however, that not all entities in the Knowledge Repository are included in the Knowledge Graph, and some criteria may influence their inclusion in the Knowledge Graph, such as:
- Sustainable social relevance.
- A sufficient number of search results for the entity in the Google index.
- Persistent public perception.
- Inclusion in a recognized dictionary or encyclopedia or specialized reference work.
It can be assumed that Google has registered significantly more long-tail entities in a knowledge repository such as the Knowledge Vault than in the Knowledge Graph and uses them for semantic search, the author argues.
By crawling the open Internet and processing natural language, Google is able to perform scalable entity and data mining independently of structured and semi-structured databases. This provides the Knowledge Vault with more and more information, even about long-tail entities.
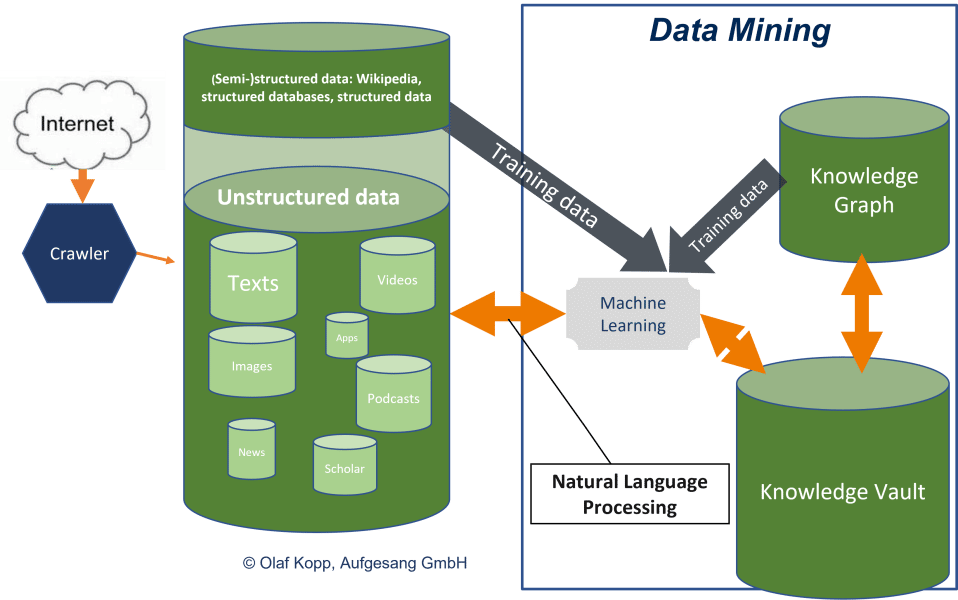
Google as a semantic search engine
At the moment, Google uses semantic search in a few areas:
- Understanding search queries or entities in search query processing.
- Understanding of entity content for ranking.
- Understanding of content and entities for data mining.
- Contextual ranking of entities for subsequent E-A-T evaluation.
Google search now relies on a search query processor to interpret search queries and compile corpora of documents relevant to the search query-this is where BERT, MUM, and RankBrain can come in.
In processing the search queries, the search terms are compared with the entities recorded in the semantic databases and, if necessary, refined or rewritten. In the next stage, search intent is determined and a suitable corpus of X content is determined.
Google uses the classic search index and its own semantic database in the form of Knowledge Graph, and, according to Kopp, an exchange between these two databases via an interface is “likely to take place.”
Then there is a rating engine consisting of several algorithms based on Hummingbird’s main algorithm, which is responsible for evaluating content and sorting it by score. The scoring is concerned with the relevance of the content in relation to the search query or search intent.
Since Google also wants to evaluate the quality of content in addition to relevance, it is also required to score according to the E-A-T criteria, which examine and evaluate the competence, authority, and trustworthiness of the domain, publisher, and/or author. Semantic entity databases can be the basis for this type of work.
Search results are then cleared of duplicates using a cleaning engine, and any penalties are taken into account.

The bottom line of this path – also well highlighted by Adriana Stein – is that Google’s goal is always to provide users with the best possible search experience. To do this, today we need semantic search, which allows us to:
- Identify and disqualify low-quality content.
- Gain a better understanding of users’ search intent-for example, is the user trying to navigate to a particular page? Is he or she looking to learn more about a topic? Is he or she interested in buying?
- Formulate answers to the questions.
- Determine what relevant data to extract from the semantic Web.
- Understand Web sites and pages in terms of topics rather than keywords.
- Integrate Google technologies in which semantic search plays a role such as Knowledge Graph, Hummingbird, RankBrain, BERT.
- Appropriately format data for inclusion in search results.
- Connect with extended and broad meaning queries when the search intent is not clear or unique.
Semantic search, search engines and SEO
Today, the understanding of search engines has evolved and as a result we have changed the way we have to work for content and page optimization, because the days of simply reverse engineering content that ranks higher are behind us and identifying keywords is no longer enough.
With semantic SEO, it becomes necessary to understand the meaning of those keywords, provide detailed information that contextualizes the keywords, and fully understand user intent, elements that are vital in an era when machine learning and natural language processing are helping search engines better understand context and consumers.
Simply put, today semantic analysis is an attempt to bridge the gap between the search algorithm, the Web pages it returns, and the search engine users.
The person launching a query wants to find something, and a search engine has two tasks to solve: understand what the user wants and match that intent to Web documents that do the best job satisfying that need (and providing a positive experience overall).
For what it is concerned, the search engine needs to understand what people want to find, using semantic analysis to better understand the intent of the search query; at the same time, as mentioned above, it needs to match the intent of the query with the Web pages it has in its index, using semantic coding that explains to the search engine what is on the page and whether it actually matches the intent of the query.
In this sense, then, semantics serves to make interactions between the search engine and its users easier, but also to help the search engine better understand (and use) the information on any given page.
In the coming years, we will most likely see an increasing impact of entities in Google search, and it is easy to assume that the more entities are recorded in the Knowledge Graph, the greater their influence on SERPs will be. The very emergence of entity-based searches clearly shows how Google is gradually organizing the indexing of information and content around an entity, and more recent innovations, such as MUM, follow the idea of semantic search.
However, there are still many ongoing challenges, and in particular that of reconciling completeness and accuracy: today, the actual scoring of documents is assigned by Hummingbird according to classical information retrieval rules, because document-level entities do not play an important role in this domain, but rather represent an important organizing element for building unweighted document corpora on the search index side. In contrast, at the domain level the influence of entities on ranking is much higher, and this is where E-A-T and its continuous evolutions come into play.
How much semantic HTML matters for ranking, Google’s words
Also speaking on the topic of semantic HTML recently was Google’s John Mueller, who devoted an episode of his #AskGooglebot series to explaining the weight that semantic elements can have in terms of potential ranking benefits and organic visibility. In summary, the Search Advocate recommends using semantic HTML because, while it is not a direct ranking factor, it helps search engines understand content and increases accessibility.
Broadly speaking, in this context semantic HTML “is when HTML elements are used to structure content based on the meaning of each element, not their appearance”; for example, the video explains, “instead of enlarging text you could use a header HTML element.”
There are many nuances on this area, so our discussion will be simplified to SEO purposes only.
What semantic HTML means
Semantic HTML refers to the use of specific HTML elements that serve to reinforce the meaning of content on a website, rather than just for its presentation, because they clearly describe their content to browsers and search engines, making the web more accessible and helping search engines understand the context of content.
For example, semantic elements such as <header>, <footer>, <article>, and <section> clearly indicate the structure of a web page, just as tags such as <nav> for navigation, <main> for main content, and <aside> for secondary content provide further details about the structure and content of a page.
As Matt Southern also points out, semantic HTML elements provide meaning and structure to web content, helping search engines and browsers better understand the content and relationships on the page.
What are the elements of semantic HTML
Thus, among the most common semantic elements in HTML we can mention:
- Headings , which are used to indicate the importance of the various sections and paragraphs, creating a hierarchy where <h1> is the most important part and, progressively, <h6> is the least relevant.
- Paragraphs are used to represent blocks of text; the <p> element defines a paragraph.
- Lists are used to organize elements; <ul> and <ol> create unordered and ordered lists, respectively, while <li> defines a list element.
- Tables structure tabular data; <table> creates a table, <tr> defines rows, <th> defines column headers, and <td> defines data cells.
- Links or anchors (<a>) create hyperlinks between pages and help show connections between content.
- Images (<img>) represent photo or graphic media resources; the alt attribute provides a textual description of the image, which helps with accessibility and SEO.
- Articles (<article>) represent independent, reusable content such as blog posts or news items.
- Sections (<section>) group related content within a document, such as chapters or parts of a document.
- Asides (<aside>) contain content tangentially related to the main content, such as sidebars or inserts.
- Figures (<figure> and <figcaption>) represent an image, diagram or illustration, along with a caption; they show the relationship between the media and the surrounding text.
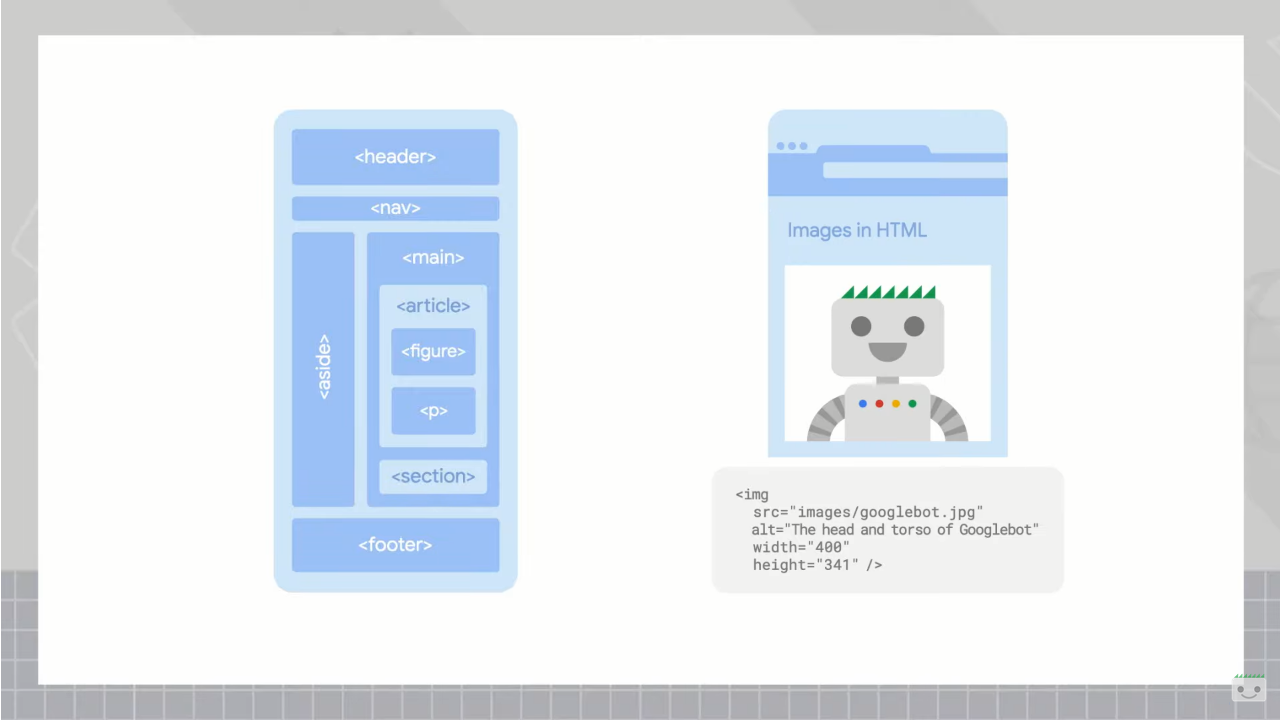
However, it is worth considering that Google’s systems are not particularly demanding or taxing with respect to the use of similar elements: for example, when grouping text, most elements are treated the same, regardless of whether it is a section, article, or div element, because the specific element used is less important than a clear structure and precise relationship between elements overall.
Semantic HTML: important for SEO, but not a direct ranking factor
And so, the use of semantic HTML elements has a significant practical function, because it helps search engines analyze the content and structure of the page, but it is not a direct ranking factor, clarifies Mueller, who explains:
“Semantic HTML helps to understand a page. However, it is not a magic multiplier for improving a website’s ranking.”
That said, in the form of an indirect relationship these elements can still positively affect a site’s organic visibility because they can improve user navigation and accessibility, which remain key best practices for achieving a good user experience. Also, no less important, they usually lead to good HTML code, which is generally a best practice across the board.
More specifically, the proper use of semantic HTML elements can help both Google and the users of our site.
- Semantic HTML and Google
When used appropriately, semantic HTML elements can benefit (also) SEO, and for example:
- Headings allow you to structure passages of text.
- Specifying images allows them to be placed in the context of relevant words and content.
- Table tags for data tables allow you to position more than just content.
- Insert anchor links instead of links that work through JavaScript
- Semantic HTML and people
Semantic HTML elements greatly enhance the experience of users of different backgrounds, including those with disabilities, particularly in these ways:
- Semantic HTML helps screen reader software deliver Web content to users who are blind or visually impaired.
- Semantic HTML ensures keyboard navigability. Elements such as <a> links and <input>/<button> forms are accessible via keyboard controls, which help users with motor impairments.
- Assistive technologies such as Braille readers and speech synthesis software benefit from the structure and meaning clarified by semantic HTML.
- Semantic elements facilitate responsive web design, ensuring that content is accessible on various devices.
- Semantic HTML future-proofs content by adhering to web standards. This means that all users will likely be able to access content even as technology advances.
Developers can create Web content understandable to humans and machines by following the principles of semantic HTML, leading to an inclusive Web experience.
For these reasons, too, Mueller concludes the video with an appeal to Web site owners to use semantic HTML, even if it is not a direct ranking factor: “Please use semantic HTML. It’s not a ranking factor, but it can help our systems better understand your content,” says the Search Advocate.
