
Search engines, main alternatives to Google
It is difficult today to imagine the Internet without Google, yet the search engine invented by Larry Page and Sergej Brin has been on the scene for just over twenty years, while the first tools in this field were active at least since the nineties. And although today Google is the absolute ruler of user searches, from mobile and desktop, there are still many alternative search engines that try to make room and gnaw market share: we found many, among those generalists, those that promise a specific attention to privacy and those that are specific to a niche reference, and we have selected a dozen.
What is a search engine
We have at our disposal a library as vast as the whole world, but there is no catalog to orient us or guide us to locate the resources we need. That would be a nightmare, wouldn’t it? Here, search engines are the catalog of this global library called the Internet, sophisticated software tools that allow us to find the information we want in the vast ocean of data that is the Web.
The process behind a search engine is fascinating: when we type a word or phrase into the search bar, the engine goes to work to analyze billions of web pages and provide us with the most relevant, and therefore suitable, results to meet our need. This work is done through sophisticated algorithms, which first scan and index the information on the web-that is, read and catalog the information on each page-and then evaluate and rank it according to its relevance and the specific criteria that have been set.
When we search for something, then, the search engine consults its index and provides us with the most relevant results.
The history of search engines is also as interesting as how they work: it all began in 1990 with “Archie,” the first search engine created by Alan Emtage, a student at McGill University in Canada. Archie was a very simple program that allowed people to search for files on public FTP servers. Since then, search engine technology has made great strides, evolving into increasingly sophisticated and powerful tools. Today, in fact, there are countless search engines, each with its own characteristics and specializations: some, such as Google, Bing, and Yahoo, are generalist search engines, capable of providing results on any topic; others, however, specialize in certain industries or types of content. For example, Amazon is a search engine for commercial products, while PubMed is dedicated to scientific research.
Each search engine has its own peculiarities: Google, for example, is famous for its ability to provide accurate and relevant results thanks to a sophisticated algorithm called PageRank, and it is considered the best search engine ever (at least, this is the most generally held opinion); Bing, on the other hand, is distinguished by its integration with Microsoft Office and its ability to provide high-quality visual results. Yahoo, while less popular than Google and Bing, does offer a number of integrated services, such as e-mail and news, that still make it a point of reference for many users.
In conclusion, whether it is finding a recipe, researching a project, or buying a product, search engines are there to help us find what we are looking for on the Web as quickly and efficiently as possible. And as technology advances, we can expect them to become smarter and more personalized.
Internet search engines, statistics about use
These tools are thus the compass for our Web journey and are an integral part of how we use the Web.
Let us try first to find out which are the most used search engines in the world, even if the first place of the ranking does not reserve any kind of surprise.
According to data from Statscounter, in fact, there is absolutely no comparison between Google and other search engines, at least in quantitative terms.
Globally, Google is used by 93 percent of people (doing two quick calculations, it means a user base of about 4 billion people in the world!), leaving its first competitor – Bing – with just 2.7 percent of the “pie”; in third place we find YANDEX with a share of 1.15 percent, slightly higher than the 1. 11 of Yahoo! and the surprising 0.51 of DuckDuckGo, which has overtaken Baidu (which continues to lose share and now touches 0.41 percent) and is preferred especially by those interested in the privacy aspect, as it is considered on average more safe than competitors linked to big brands.
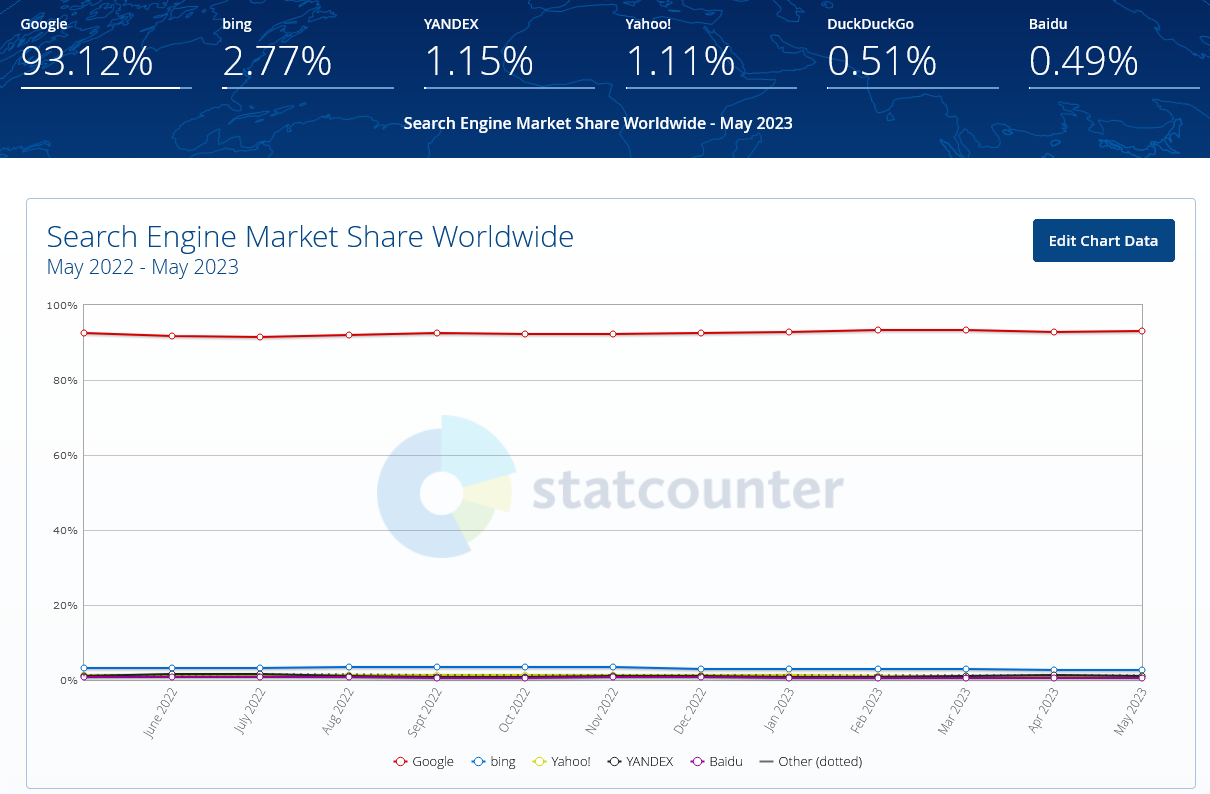
The other alternative search engines to Google, and in particular YANDEX RU, Sogou, Naver, Ecosia, Haosou, Seznam, Shenma, CocCoc, Qwant, MSN, Daum, and Mail.ru, do not reach the percentage point either.
The graph above shows aggregate data for all platforms, but the segmented analysis does not offer too different results: from mobile, for example, Google is chosen by more than 96 percent of users searching for information online (also due to the dominance of Android), surpassing in this case Yahoo!, Yandex, and Baidu, which make their case on the strength of their narrow territoriality.
From the desktop, on the other hand, Google’s popularity falls below 88 percent and there is a greater preference for other search engines, such as Bing (6.76), Yahoo! (2.07), Yandex (1.5) and DuckDuckGo (0.6).
History of the online search engines
Today’s picture is very different from that of 33 years ago, when the first Internet search engine began to move: it was back in September 1990 that, in fact, we saw the birth of Archie, created by Alan Emtage to connect to all the servers in the archives of Mcgill University in Montreal (Canada) and download the list of public files, so as to find a match with the user’s request in the database and show the ftp address from which to download the file.
A system far from the current concept of search engine, but we must remember that at that time the world wide web was still a protocol (the first description of its operation dates back to 1989, while the first site to 1991) and the Internet was a tool used mainly by academics to exchange files and software.
Archie stands out, and in his wake the first examples of Web search engine that really allow the query of pages are born later. In 1994 Web Crawler debuted, made by Brian Pinkerton at the University of Washington, which for the first time indexes the entire text of web pages and looks for a match based on the criteria provided by the user. In the same year also Aliweb, Lycos (still in business) and especially Yahoo! appear, which start a “small revolution”.
In particular, if Aliweb allows each user to send the address of their site, so as to include it in the indexed list, Lycos (which today is still active as an entertainment web portal) is immediately appreciated for the great power in inspecting the web and for innovative search system, which gives weight to the searches already performed, introduces the first signals of relevance and allows to approximate the words used for the survey. Its archive, which already after the first month of operation had 394 thousand documents, in the following two years expanded to exceed 60 million in November 1996.
Well known is then the story of Yahoo! , designed by David Filo and Jerry Yang, who surpasses the competitors because, first, also provides a description of the indexed site. In addition, the Yahoo! search engine is also the first to include commercial sites, charging an annual fee for entry into the archive.
The evolution of search engines
Still during these years – the same in which you find the first occurrences of the word SEO to define search engine optimization – begin to appear on the Web many other search engines, more or less famous, like Excite, Ask and above all AltaVista – for years the best search engine for its speed, almost unlimited bandwidth for times and the ability to understand queries in a natural language, before being outclassed by Google and then acquired, in 2003, by Yahoo!.
In the chronological list of search engines you can also come across a mysterious name, BackRub, a search engine created to evaluate how to index web pages on the basis of links that link to that same page: that is, more a web page is linked from other sites, the more its authority increases. That’s what Google’s Pagerank does (and has done for years) because in fact Backrub is the name of the first project by Sergey Brin and Larry Page, which in 1998 will give life to the search engine that we all know today – and that looks more and more like an answer engine, as we habitually call it now.
The history of search engines then had other key steps, such as improvements to web crawlers, refinement of categorization and web indexing, the introduction of new protocols such as robots.txt to allow webmasters to control which web pages should be scanned, the introduction of voice search and the application of sophisticated technologies to ensure to provide the best answers to the users’ queries.
Search engines: what they are and what they are for
Today we use the search engine on every device and in any way – also through voice searches – and it seems obvious to us to get precise answers in the blink of an eye, “regardless” of how our query is formulated. We rely on the intelligence of Google and other search engines, which use machine learning to process and classify information and have become able to understand natural human language.
Modern search engines work thanks to complex algorithms that take a search query and return results that are usually quite accurate, presenting the user with valuable information in the midst of a vast data mine.
Obviously, it has not always been the case, as those who have more experience remember, and the first search engine tools were just able to read and catalogue documents within the “world wide web”, making them available to users in the so-called “SERP” (Search Engine Result Page) formed from the “query” (question) asked by a person to the Net.
Until not too many years ago, in fact, it was necessary to know the exact formulation of the title of a website to find it, or it was necessary to only rely on the exact match between the keyword of the query and those present in the content, and again (and also for this) The search results were full of spam and getting new content indexed by search engines could take weeks of time.
Anyway, during this period the function of the search engines has not changed too much, and they essentially perform 3 basic actions:
- Information retrieval
When a user executes a query, it asks the engines to return results, which are classified hierarchically using specific signals, which usually also consider trust and relevance of the topic.
- Web scan
The search engine navigates the web in a methodical and automated way – the crawl stage.
- Indexing
In the simplest and most popular form of operation, pages are analyzed for specific titles, headers and fields and added to the specific index of the search engine – indexing stage.
How search engines work
A search engine is a program that searches the Web sites based on keyword search terms, scanning the Web to search for the best occurrences that respond to the query entered by the user, to which it returns Serps, pages that contain a list of sites that the algorithm has decreed to be relevant or linked to the searched keyword.
Web search engines catalog the world wide web using a spider, or web crawler, of the automated robots to scan the web that are used precisely for indexing content and scan and evaluate the content of the pages of the site and of the archives of information on the web.
What is different between Google and other search engines is the method to determine the relevance of a page with respect to the user’s query: of course, there is no official information on the criteria used to create the rankings – even Google, for example, we know the 200 unofficial ranking factors – but we can say that the best search engines are those that manage to ensure the results actually more relevant and precise, which appear in the top positions of the SERP.
The best search engines as an alternative to Google
We have come to the present day, dominated by Google which, inevitably, is also the reference point of the efforts of the SEO, which is the activity of site optimization to try and achieve the highest possible visibility on search engines (plural).
This means that, although used by a smaller or marginal share of users, we must not neglect to edit the ranking of the pages of our site on search engines alternative to Google, that can offer good feedback in terms of organic traffic on keyword for which it is difficult to emerge on Google, for example.
In addition to general search engines, which scan and archive the entire Web, there are also search engines specialized in niches, for example to search for blogs, job listings or other specific topics (BlogSearchEngine, search engine for blogs, Indeed and Monster for the job search and SongMeanings and LyricsMode for music lyrics), and therefore offer users information that meets their primary needs. Still, there are also deep web search engines, which act in areas of the Internet that do not follow normal indexing and therefore cannot be easily found and indexed by crawlers (such as Deep Dyve, a deep web search engine for magazines and academic articles).
Other search engines
Today there are several alternative web search engines that are capable of delivering quality results like Google – or even better, in reference to some specific aspects such as privacy, which is the sore point of Big G.
Some of these are region-specific – in particular, for China and Russia – while others are accessible to a global audience, but in any case the search engine search functionalities remains the same. Also, more interesting aspect, even if they are not (yet) so known they still serve millions of search queries per day, and therefore can represent an interesting business opportunity.
The new trend: anonymous search engines
In addition to efficiency, however, users today are increasingly demanding another prerogative from search engines, namely security and respect for private data, through first and foremost the inability to track sessions and activities (which therefore also prevents Google’s standard commercial profiling, which we commonly see in the targeted ads that appear in the Ads circuit).
Thus, so-called anonymous or private search engines, which do not store search information, maintain user privacy, and, in some cases, do not collect data such as IP addresses, browser fingerprints, and location information, are making inroads.
Depending on the level of security, an anonymous search engine allows the user to do classic searches but does not keep track of these activities, although the privacy offered is not always equal (it depends on the search engine’s business model and is generally greater when combined with the use of a VPN, which helps increase anonymity).
Among the main alternatives in the field of private search engines are names such as Startpage, DuckDuckGo, Qwant, and Swisscows, which, however, continue to fall short of high levels of popularity, partly because of issues related to the lack of fulfillment of privacy “promises” (a few weeks ago, for example, Wired USA discovered a kind of flaw in DuckDuckGo’s anonymous system, which allegedly created a privacy exception for Microsoft, its business partner).
In principle, however, anonymous search engines function in the same way as Google or Bing (which represent, in the view of those concerned about data security, the evil behemoths that have been profiting off users by implementing shady privacy-violating tactics in recent years) and thus allow instant access to any information desired, anytime, anywhere.
In fact, there are two major types of private search engines: the pure search engine, which has its own index and, upon receiving a query, scans several Web sites to gather information related to the desired answers, and a second type, also known as meta-search or proxy search engines, which basically acts as a bridge between search engines like Google and its users, thus limiting Big G’s access to all classic browsing data.
Online search engines: list of the most used beyond Google
Deciding which is the best search engine is not easy, however, because the qualification depends on the unique desires and needs of the user, but nonetheless the following list presents what are the most popular, valued and used search engines beyond Google.
- Bing
The main alternative to Google seems to be Bing, the search engine of Microsoft.
It is already from the nineties, really, that the American company has tried the success also in this field, launching between 1998 and 1999 MSN (which included internalized technologies with the acquisition of different search engines such as Inktomi, Looksmart and Altavista, through collaboration with Yahoo!), then Live Search (2006, also attempting to set it as the default search engine for the Internet Explorer browser), and then in 2009 Bing. The breakthrough came in 2012, when Yahoo contacted Bing with an offer to share its search platform, and today Microsoft’s search engine is really a possible alternative to Google.
From the technical point of view, Bing uses an exclusive algorithm for scanning and indexing purposes, and therefore its Serps can also be very different from those provided by a Google search, with variations also in the answers through featured snippets. In addition, it points to the feature of being a “decision engine“, offering search suggestions in the side column and providing extra search options.
According to experts, moreover, the GUI image search of Bing is superior to that of its rival and much more intuitive, while the video search service is clean and does not suffer from bias against Youtube instead Big G. Anyway, There are great affinities between Google and Bing, as we told some time ago.
- Yahoo! Search
Yahoo! is another US giant: still today it is one of the most popular email providers in the world and also its search engine, Yahoo! Search , continues to be used globally, despite the emergence of other competitors and a rather troubled business history.
Over the years, in fact, the search engine of Yahoo! has used the Google systems first and then the Bing ones to provide results (and then, in practice, the rankings of Yahoo! Search provide the same results displayed by Bing); today it is available in 38 languages and is able to return results related to text content, images, videos and news, with search forms for local information, maps and purchases.
- Baidu
Baidu is the main Chinese-language search engine – recalling that in China there is an indefinite government block, popularly known as Great Firewall, on all Google services – and was created by Robin Li, who in 1996 had launched RankDex, that used an algorithm similar to Google’s Pagerank (which only came two years later).
For the construction of Baidu, Li has studied Google not only with the principle of providing quality search results, but also important services and features for users, especially pushing on voice-assisted search.
- Yandex
Yandex is the largest search engine in Russia, where it holds almost half of the market, and was launched online as early as 1997 (it is therefore older than Google); in addition, it is also used in Belarus, Kazakhstan, Turkey and Ukraine.
Its name is the synthesized form of Yet Another Indexer, and was the first search engine that was monetized to sell ads: it began to provide contextual ads on the search engine results page in 1998, two years before Google.
Today it is a search engine overall easy to use, and makes available to users a suite of some rather interesting tools, called Yandex Technologies.
- DuckDuckGo
It is one of the favorite and most trending search engines of recent years, chosen especially by users who have fears about the issues of privacy and personal data processing through Google (which, as is well known, uses this information to provide a personalized search experience).
Founded by Gabriel Weinberg in 2008, DuckDuckGo has earned a name as a non-profit search engine: it focuses more on providing organic results to users than personalized ads, it neither collects nor stores personal data and, consequently, the search results remain the same regardless of the user who performs the query.
However, this search engine does not use a private system to generate results, but uses 400 different algorithmic sources, including Yahoo! Ask, Wolfram Alpha, Bing, Yandex, Wikipedia and the internal Web crawler Duckduckbot.
- Ask
Ask Jeeves was one of the first search engines in the history of the Web, launched in 1996 as a system based on questions and answers from users: in practice, most questions receive answers from other users or are in the form of surveys.
It changes its name in 2006 simply becoming Ask, but its success decreases with the growth of Google: today it continues to be used, also characterized by the ability to preview a Web page before clicking on it, unlike other search engines. Its layout is clean and the grouping of results is practical, but its general search functionality does not have the level of quality and depth assured by Google or Bing.
- Ecosia
Each search on Google contributes concretely to create CO2: it may surprise, but even a simple query has an environmental impact. That is why, in 2009, was born Ecosia, the green and sustainable search engine that promises to plant trees to compensate for harmful emissions, using the revenues generated by queries.
In practice, the research results on Ecosia – which are based on the Bing system, have servers that work 100% with renewable energy and do not encourage third-party trackers nor sell data to advertisers – present organic pages and a series of ads: When the user clicks on an ad, Ecosia gets a small fee; on average, with about 45 searches we are able to finance the operations to plant a tree. Furthermore, in terms of transparency, it is possible to read the monthly financial reports that inform users about the actual investment of the revenue generated by their searches.
- Brave Search
Brave was born as a web browser (presented as “three to six times faster than Chrome”) and launched a beta version of an alternative search engine to Google, private, independent and user-focused.
Brave Search guarantees security and privacy: it blocks ads in the content you visit, does not track or profile users based on their search queries, prevents malwares and prevents third parties from tracking activities.
The project is directed by Brendan Eich, creator of the JavaScript programming language and co-founder of Mozilla, who acquired the open search engine platform Tailcat, created by Cliqz, using the technology to develop and refine Brave Search.
- Swisscows
Absolute privacy is also the promise of Swisscows, which calls itself “a family-friendly semantic search engine”: it makes it clear to respect the privacy of users and not to collect, store or track data, but also to strictly prohibit violence and pornography to children under 18, providing content suitable for families and monitoring the types of content shown on the web to children.
To determine the context of a user’s query, Swisscows uses artificial intelligence, which should ensure surprising accuracy in answering questions.
- Startpage
It is a long history that of StartPage, launched in the Netherlands in 2006 and today evolved into a sort of “Google with more privacy”: this search engine, in fact, uses the algorithmic systems of Mountain View to generate their own SERPs, but refuses tracking and does not collect or sell browsing data, ensuring the user’s anomime.
When we launch a search query in StartPage, we have the option to select a specific region for the results, activate the family filter and configure a number of other settings without having to log in.
- Qwant
From the European Union comes also Qwant, a search engine launched in 2013 that has its own indexing engine (rare case in the Old Continent), even then the management has admitted that most of the research is processed by Bing.
Its system does not collect user data and does not use filter bubbles; the search engine is available in 26 languages and processes over 10 million search queries every day, and also features the Qwant Junior version that automatically filters out content unsuitable for children.
- Naver
Naver is a South Korean online platform that developed its own search engine in 1999.
Often referred to as the “South Korean Google“, Naver was the first operator in the world to introduce comprehensive search capabilities, such as compiling search results from various categories and listing them on a single page. In addition, over the years it has introduced a range of new services, such as news, emails and a platform of questions and answers.
- Neeva
Our overview concludes with one of the newest search engines on the market: Neeva was created by Sridhar Ramaswamy and Vivek Raghunathan, former Google executives who wanted to offer a search experience without advertising and without affiliations.
The business model to achieve this goal is the subscription formula (about $5 per month, after a free trial period of four months in which you can check how Neeva’s results behave compared to those of competitors), which ensures the maintenance of privacy and shows the search results edited by the Web and customized files.
The search engine is powered by Microsoft Bing, weather information is provided by weather.com, stock data from Intrinio and maps from Apple. After not even two years, Neeva shut down on June 2, 2023; as Ramaswamy and Raghunathan wrote, “it is one thing to build a search engine, and a completely different thing to convince regular users of the need to switch to a better choice,” especially if it is paid.
