
Entity and SEO: how to optimize and exploit entities according to Google
Things, not strings. It was 2012 when Google’s then senior vice president Amit Singhal used this expression to introduce the Knowledge Graph and its innovative approach, which would shortly be applied to Search and SEO in general. In a little more than a decade, the landscape has evolved further, and today Semantic Web, graphs, and especially entities are essential components of Search and modern SEO, working on multiple factors to provide useful answers, such as context, user intent, and relationships between words. Underlying this is precisely the concept of entities, which is perhaps the most complex to understand, and is the core of the semantic web and the key by which search algorithms are able to identify topics and relate them to each other.Entities for Google are precisely the nodes that allow us to understand the connections between various terms, the needs expressed by users, and the context in which these entities exist and intertwine. For this reason, working on entity optimization in our content is one of the fronts toward which to direct SEO activity, moving beyond the old concepts of keywords.
What is an entity according to Google
The definition of entity comes directly out of a Google’s patent, already registered in 2012 and constantly updated throughout the years in order to adapt it to new technologies and the algorithm’s evolution, immediately used to build the Knowledge Graph but than also extended to the Research as a whole. The document reads that, to the meaning we are interested in, an entity is
“a thing or concept that is peculiar, unique, well defined e discernible“.
More specifically, an entity can be a person, a place, an object, an idea, an abstract concept, a practical element or any combination of these – Google’s team explains – and, generally speaking, entities include things or concepts linguistically represented by nouns.
Understanding entities: examples and explanations
Therefore, entities are not simply names or physical objects, given the fact that Google succeeded in a step further: an entity could be an idea or theory (such as the theorem of Pythagoras), an adjective (like a colour), an abstract concept (a unicorn), a globally interesting topic (global warming), a relevant date and so on, so that everything can be gathered in a unique way without any chance of confusion.
In addition, another difference from classical keywords, which are tied to language-specific terms, an entity carries meaning and is independent of the language and similar keywords that designate it, and can be found with a number of different search terms. This also reduces ambiguity in translations of words, which have sometimes multiple meanings depending on contexts and nuances that can be difficult to understand for those who do not master that language-and also for search engine machines.
These things, to borrow Singal’s words, have accompanied the evolution of the search engine and its algorithms, first with the introduction of Hummingbird and then later with RankBrain, with which Google veered to a different approach to understanding the meaning and subject matter covered in a web page, relying no longer solely and simply on keywords, but on analyzing the concepts contained in a text.
This has become even more evident in recent years, with the introduction of Google BERT and, later, Google MUM, two technologies based on artificial intelligence and machine learning applied to SERPs, which are able to better understand the language of users and deeply analyze their queries and needs, going beyond the literal meaning of the query (understood as a string of characters or words) to identify intent.
And then we must not forget the constant increase in structured data and schema.org markup, the pieces of information we provide through our pages to enable crawlers to better understand the content and, indeed, the entities and relationships present.
All this data helps search engines to provide users with more on-topic results, focused on real intentions, with possible insights (see also the exponential growth of the boxes People also ask for in SERPs), but most importantly to reduce misunderstandings and minimize out-of-focus results.
What entities are useful for
On a general level, entity can thus be a person, a place, a concept, a concrete thing, i.e., anything we can represent linguistically; for Google, it is the way it tries to train its algorithms to understand language naturally, as we do automatically (pardon the pun).
We can think of these semantic entities as sets of related words that are very frequent in content dealing with a particular topic or concept and transfer the meanings usually associated with a keyword: by noticing these relationships and correlations, the machines are able to digest and understand the meaning of the concept.
The algorithm does not search and analyze a simple keyword, then, but a wide range of interrelated information, through which it processes a detailed and in-depth response to the query from the user. These entities are stored and grouped in Google’s Knowledge Graph, the graph of knowledge that represents, precisely, the network of information and data across the web and provides search engines with a precise context in which to scan a page and a site.
It is precisely context, then, that becomes a crucial concept, the key variable for determining the degree of relevance of a piece of content against a given search query, and consequently for understanding the person’s intent and removing ambiguity about the content he or she discovers.
We are talking, again, about semantic SEO, which is capable of going beyond the simple character strings of the query to focus on the user’s intent, and which intercepts the direction taken by search engines, which today no longer reward content with lots of keywords or that relies on parameters such as keyword density and the like, but pages that know how to respond to people’s needs for information and entertainment.
Google’s entity database
In the wake of various analysts’ considerations, which are also based on the study of Mountain View’s most recent original patents, we can speculate that Google is building and developing its entity database (which some time ago had about 5 billion entities and over 500 billion entity owners) using two distinct methods, copying existing entities and discovering new ones.
In the first case, the search engine identifies entities that are already known (thanks to reliable sources such as Wikipedia and Imdb, for example) and aligns them with the real world: the disadvantage is that the timeframe for reporting new entities or updating old ones depends on the sources, and thus Google depends on them to provide relevant content.
To overcome this limitation, the group has patented some methods for discovering new entities from unstructured data available on the Web, employing two different strategies. Specifically, the search engine can use use known entities and check, through syntax or other signals (e.g., frequent appearance in documents on the same topic), whether they are related to unknown entities to be considered. Another method measures the value of an entity against the size of its scope, from which it follows that it is easier to become an authoritative entity in a narrow field than to emerge in a broad niche.
Entities and Google: how entity ranking works
As mentioned earlier, Google’s Knowledge Graph plays an important role in entity SEO, and it is precisely an analysis of a patent related to this tool that gives us an idea of how entity relationship determination works.
The analysis was performed by Dave Davies in 2017 based on Google US Patent No. US 2015/0331866 A1: although it is an “old” study, the information reported can still give us useful insight into the basis of modern entity relationships and the way we think about them.
According to Davies‘ research, the classification of entities in Search considers four factors: relatedness (kinship), notability, contribution, and reward; Google’s algorithm examines these factors and uses them to create a network of connections between different entities and to make the search more effective for the user. Technically, each entity is assigned a unique ID number, which then “transforms” it into code and data to allow it to be mapped into the knowledge graph.
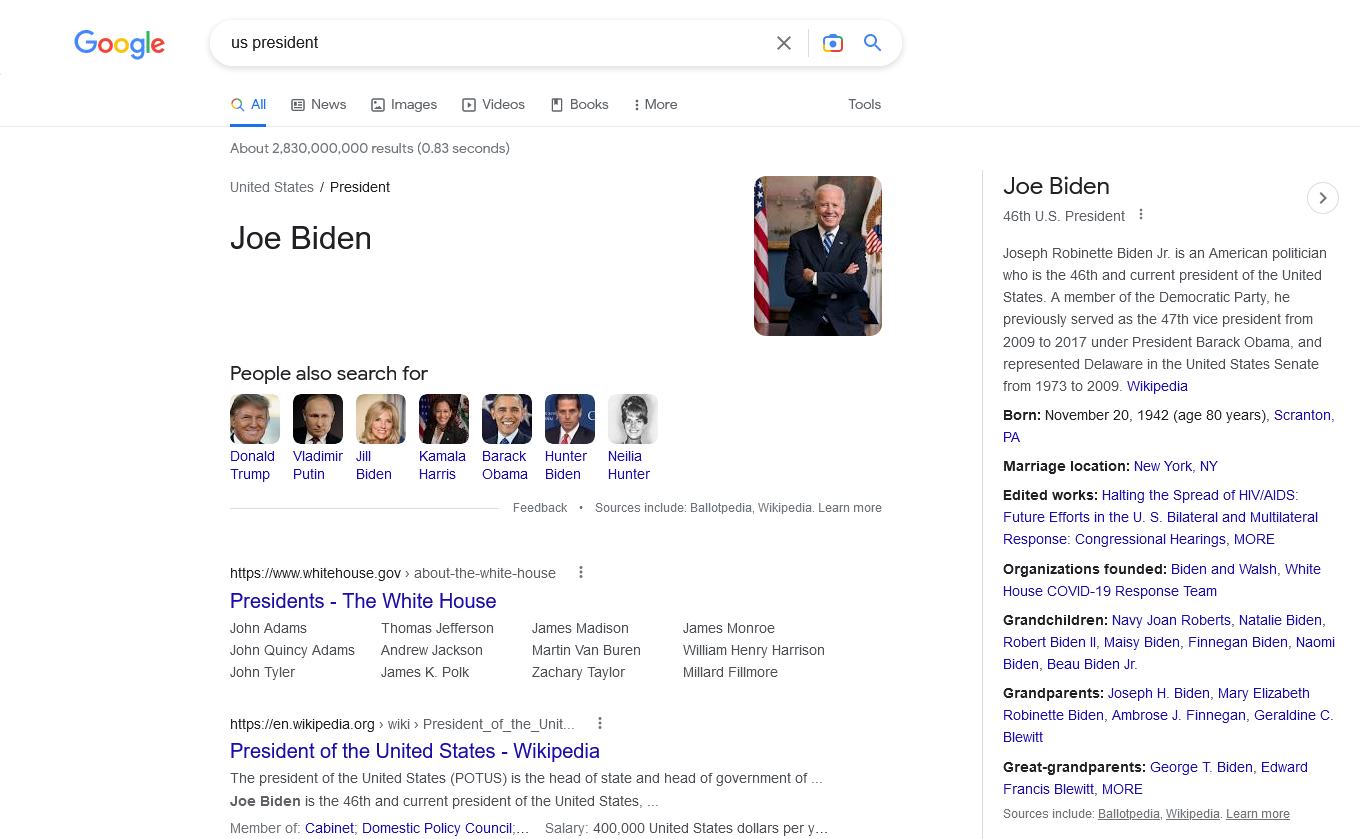
- Correlation allows us to understand the link between terms in the query, and to show different SERPs (on Google USA) that distinguish between U.S. president and U.S. presidents:

- Notability. Google uses a formula (detailed in the patent) to determine entity notability. Beyond the formula, it notes that entities are more valuable in low-competition categories and are more valuable when they have more links, reviews, mentions, and relevance. Basically, what it means is that “being a big fish in a small pond gives greater notoriety than being the same fish swimming in the ocean.”
- Contribution, referring to how much an entity contributes to a topic: it is determined by external signals such as or reviews, and a review or backlink from a more established Web site will carry more weight than a less respected one.
- Rewards. This is exactly what it means, so a measure of the relevant awards received by an entity, such as the Nobel Prize or Academy Award. The more prestigious the award, the greater the value placed on the entity.
Putting all this information together, for each query Google determines the kinship, notoriety, contribution, and awards of other entities and assigns values, a kind of final score for each possible entity.
If we search for “best actors,” for example, the SERP returns a list in which mostly Oscar winners for best actor appear, because Google tries to provide an “objective” answer even to such a subjective topic, considering the four factors of ranking entities as a ranking reference-in this sense, the best actor award at the Academy Awards, the famous Oscar, represents a “quality” indicator. In practice, the focus on analyzing “awards” and the “weight” to these awards allows Google to identify and show the most relevant entities
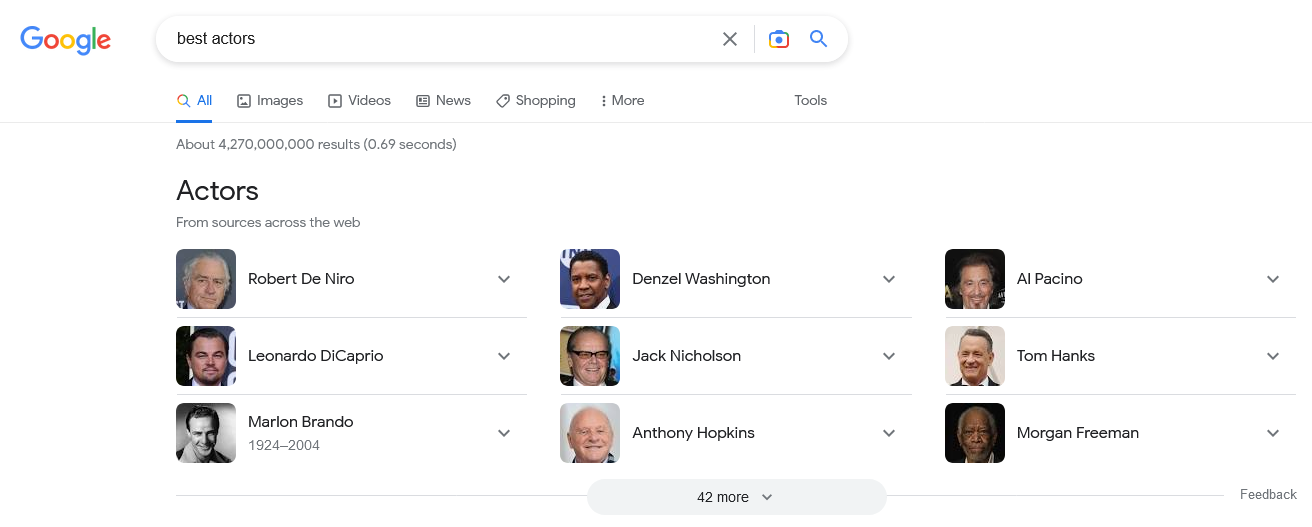
Other useful information about how this mechanism works includes the presence of an entity database, which simply stores entities and their connections and serves Google to avoid having to process the best results every time a query is run, and the ranking of entities based on some sort of quality score that can include freshness, previous selections by users, incoming links, and probably outgoing links.
There are also methods that allow Google to infer context for multiple entities with the same name: for example, Philadelphia may refer to the city, cream cheese, and the movie, but if we include words such as “where” in the query we direct the search to the U.S. city, “actor” or “plot” to the movie, and “pairings” or “calories” to the food. In this way, Google can determine entities and their relationship when the data is unstructured (information that does not have a predefined data model or is not organized in a predefined way) and can also learn new entities.
Ties between entities and link importance
Trying to simplify fairly complicated concepts, we could say that Google uses a set of systems to evaluate ties among entities and to give importance to each and every one of them: for instance, it can establish a correlation between two entities comparing the number of times in which they are both quoted on web pages.
An external factor of comprehension are the contribution supplied by various sources, such as reviews, third-party published charts and so on: in this specific case, the value is also reasoned on the authority of the source. A particular typology is the one that concerns prizes, used to determine the perceived entity value compared to an activity, professional field or competence.
Furthermore, also links and mentions play a relevant role, given the fact that they are used as factor to measure the importance (notability) of the entity based on the way it refers to a query or another entity: the algorithm cross-checks the entity’s global popularity and so its number of backlinks, mentions on social media etc., and ponders it compared to the value of the specific kind of entity.
Let’s get back to talk about links value, but in a different meaning (maybe not that much, really): we have defined them as “votes” from site to site, but linkings are also a way to create a conjunction between entities (such as the linking site and the linked one), so are likely considered entities the pages’ PageRank, the used anchor text, the topic relevance, etc.
Schema.org and the kind of data structured to build semantic web
First of all, though, the kind of tools we have to communicate entities to Google (and to propose our contents as such) are structured data and schema.org ‘s info, and we need them to implement semantic web. Meaning, the new (and not that much already) way to directly report to the search engine all the info included into and behind web pages (brands, authors…), so that Google could make the gathering and elaboration of data faster and its answers to the search query quicker and more precise.
Using entities and their data, the algorithm can actually compute the probabilities to intercept the user’s real intent with more accuracy and at the same time – from language and used tone – to understand if the result will be positive or negative.
In essence, as we were saying in the past dedicated articles (specifically this one about microformats), in order to define entities and to provide them to search engines as data you have to use structured data, so to highlight a web page’s topic and the correlation among various entities.
Entities within SEO
Reaching our professional topics, inside the SEO field entities also are the elements to the core of the users’ researches: a product to buy, a brand, a piece of news, kitchen recipes are all entities to the search engine. Effectively using scheme’s vocabulary and scructured data we directly communicate to Google – in a focused and errorless language – our pages and website’s topics, giving the algorithm the actual chance of a better understanding, without any confusion.
Why work on SEO optimization of entities?
We said it long ago with the provocation “there is no keyword“: the current trend of search engines is to overcome the limitations imposed by just understanding (and searching for) keywords, going rather to identify the topics and context activated by those keywords. In this way, we overcome the typical critical issues of keywords, which can be too literal and contrived and bring ambiguity, when, for example, the same term refers to different concepts, and only a thorough analysis of the context can precisely resolve doubts.
And so, Google and other search engines are moving more and more in the direction of examining the combination of keywords in a query and, thanks to entities, getting to understand what content is relevant through page analysis that no longer relies on the simplistic coincidence of topic with keywords-which is why, for some time now, we have been repeating that we need to work on expanding our content and extending the semantic field of keywords with other related terms belonging to the same entity and intent, which help crawlers to better define and understand the context.
The methods for implementing entities on the site
Implementing entities on content comes with its own set of challenges because the technical infrastructure is changing and the schema.org vocabulary is constantly being updated, so this requires setting up constant monitoring and maintenance to ensure that the added structured data is effective and error-free.
The first step is to create and reinforce a brand identity for our brand or for ourselves by trying to enter Google’s knowledge graph through a personal or brand knowledge panel; for a business, then, it is crucial to activate a Business Profile (formerly Google My Business), which, while not automatically making the brand an entity is still a useful step, because Google will use this tab to learn credible information and create links between the site and other local entities.
Critical then is the use of structured data, which can tell crawlers which parts of the content are entities and with which attributes. For example, the local business schema can serve to link a business to other nearby geographic entities, increasing its visibility in local search; other markup such as organization, person, and author, on the other hand, can help create connections between entities on the same website, but also in other domains, reinforcing the “network” concept.
On the practical side, then, we can check to include entities relevant to our content every time we publish an article, searching for other entities either through the Search system (taking advantage, for example, of the suggestions displayed in the other results to figure out which topics and themes Google sees as related to the main topic of our content), or through Wikipedia pages or other such tools, which relate known entities.
How to better communicate entities on the site and in the content
So there are some steps and interventions that we can put into practice to try to increase the value of our site as an entity (which in turn contains countless other entities), that is, to strengthen its value and relationships with that with the other Web elements toward which we want to establish an association.
Some operations are more “simple” and should be routine by now, such as adding schema.org to the site, using error-free structured data, creating a Business Profile sheet if we are a physically based business and keeping it up to date, having a relevant backlink profile thanks also to more strategic link building, as well as of course prioritizing the creation of quality content that deals with topics in a broad and deep way and responds to people’s search intent.
Content strategy and entity optimization
In conclusion, it is no longer possible to ignore the growing importance that entities have and will have on SEO, both for search engine crawling and for our own content.
This also requires us to change our approach to content strategy: currently, for a solid strategy we need to consider (at the very least) the overall volume of searches performed and the intent that Google chooses to display with query results using its algorithms. But we need to study what features appear in SERPs and what kind of visibility they have, because they often exceed the old positioning via links.
In this sense, optimizing entities through schema and structured data offers an opportunity to outperform competitors who are still fossilized on the old keyword race, because with this metadata we can help Google’s effort to map the content of the world (virtual and otherwise) and make it easier for the search engine to understand the content of our web page and recognize entities and their relationship to each other. If we can communicate with greater precision to the crawler what exactly the content of the web page is about, simplifying its technical indexing, the search engine will be able to select such content more quickly and with more certainty for a corresponding query, ranking it higher in SERPs or showing, for example, the result as a rich snippet that can attract users online.
