
Google Knowledge Panel, guide to the Entities informative database
Let us introduce to you Google’s Knowledge Graph, the huge database of information that allows Google to provide immediate, concrete and, above all, relevant answers to users’ questions in the form of a data-rich information box that appears in SERPs for certain queries. Today we are going to delve into the workings of this valuable knowledge base on the Web, which represents a kind of giant virtual encyclopedia of facts, to also understand how it can influence SEO.
What is Google’s Knowledge Graph
According to Google’s directions, the Knowledge Graph is a collection of automatically generated information from various sources, displayed with a visual layout similar to that of the latest rich results (to the point that it can be difficult to distinguish at a glance between a rich result and an information pane, admit from Big G).
Knowledge Graph results cover so many elements (places, people, companies, and more), on closer inspection some of the entities known to Google, which are shown with additional data such as logo, referring site name, social profile link, and so on, feeds possibly thanks to data provided via schema.org markups.
We can think of this graph as a network of information, a cross between an encyclopedia and a database, which functions practically as an interconnected map of data in which the associated points are linked semantically, branching off in all directions and connecting to many other elements. In this way, it manages to provide relevant context to the query, resolving initial ambiguities and providing more meaning to the answers: that is, it turns data into knowledge.
The history of Google’s Knowledge Graph
Google announced its Knowledge Graph on May 16, 2012, with an article by Amit Singhal, the company’s senior VP at the time, presenting the feature as “an intelligent model, a graph in geek jargon, that encompasses real-world entities and their relationships to each other,” i.e. – in an expression that later came to be celebrated – encompassing “things, not strings“.
Initially available only in English, the tool was expanded in late 2012 for Spanish, French, German, Portuguese, Japanese, Russian, and Italian languages, continuing to expand for other versions of Google (for example, Bengali support was added in March 2017).
The information covered by Google’s Knowledge Graph has grown rapidly: at the start it contained 500 million objects, as well as more than 3.5 billion facts and relationships between these different objects, but by the end of 2012 it already included 570 million entities and 18 billion facts; by mid-2016, then, Google reported holding 70 billion facts and responding via graph to “about a third” of the 100 billion monthly searches it handles; in one of the last disclosures on the topic, then, in May 2020, the reach had increased to over 500 billion facts across 5 billion entities, covering much of human knowledge, from niche topics to public interest topics such as medicine and science.
How the Knowledge Graph Works
The Knowledge Graph is a semantic search function that, since its inception, has aimed to provide users with accurate and complete answers, anticipating the classic content proposed in SERPs by Web resources and significantly improving the value of information returned by Google searches. More precisely, it serves to identify and return publicly known factual information to people when algorithms deem it to be useful.
There is no official documentation on how the Google Knowledge Graph is implemented, but we do know, however, that it retrieves facts and information about entities from many sources, particularly from open source and licensed databases, such as Freebase, CIA World Factbook, and Wikipedia, among others, and from shared materials on the Web, by scraping quality and relevant content from other sites, to store data on a much broader and deeper scale. Precisely for the latter aspect, Google has received much criticism over time because the answers provided in the box did not correctly report attribution nor source citations. On the official fact sheet help page, today Google specifies that the graph “licenses data to provide information such as sports scores, stock quotes, and weather forecasts; it also receives factual information directly from content owners in various ways, such as from those who suggest changes to the fact sheets they have claimed.”
The system is optimized based on what people search for and what Google discovers on the Web, Singhal said earlier, and is essentially for “searching for things, people or places that Google knows about (landmarks, celebrities, cities, sports teams, buildings, geographic features, movies, celestial objects, artwork and more) and immediately getting relevant information for the query.” This is, in the search engine’s view, “a key first step toward building the next generation of search, drawing on the collective intelligence of the Web and understanding the world a little more as people do,” followed by the evolutions of machine learning, artificial intelligence, neural matching and natural language, which are more closely aligned (just think of all the AI applications in Search, for example).
Because of its characteristics of speed and ease of understanding, the Knowledge Graph is used to answer direct voice queries in the Google Assistant and Google Home voice queries.
Basically, the Knowledge Graph is activated based on the search query and information stored in its database, whereby Google’s algorithms combine relevant data and facts to make life easier for the user. In response to his query, in fact, the person can display in a prominent position in SERP (usually at the top or right side of the search results from desktop, at the top only from mobile) the main information succinctly enclosed in the form of information boxes.

Be careful, however, not to confuse the Knowledge Graph with another visually similar feature, namely Google’s Knowledge Panel: the latter is a visualization of data elements connected through the graph and can represent a subset of graph data, but it is precisely a different feature. In addition, the Knowledge Graph is a less visual record of topics: we can think of it as a mind map that not only understands what each entity is, but can keep track of how different entities connect to each other, in order to refine the query and select the most relevant information to quickly show to the user.
The usefulness of the Knowledge Graph
Understanding why the Knowledge Graph is useful is very simple: the Google search engine is able to associate queries with an object and relate multiple objects logically and semantically to provide the user with a faster and more accurate search.
Its introduction represented a momentous change in search from simple direct association by “strings” (words to other words) to understanding things and concepts; more, the graph marks the real beginning of Google’s attempts to understand search intent and the relationship between entities.
In fact, the box summarizes the main information about the subject of the query, thus speeding up the user’s search and satisfying the search intent instantaneously and more quickly than the classic consultation of SERPs and sites. The information box appears on the right side of the results page, with data about the searched entity and any additional news based on the type of query typed.
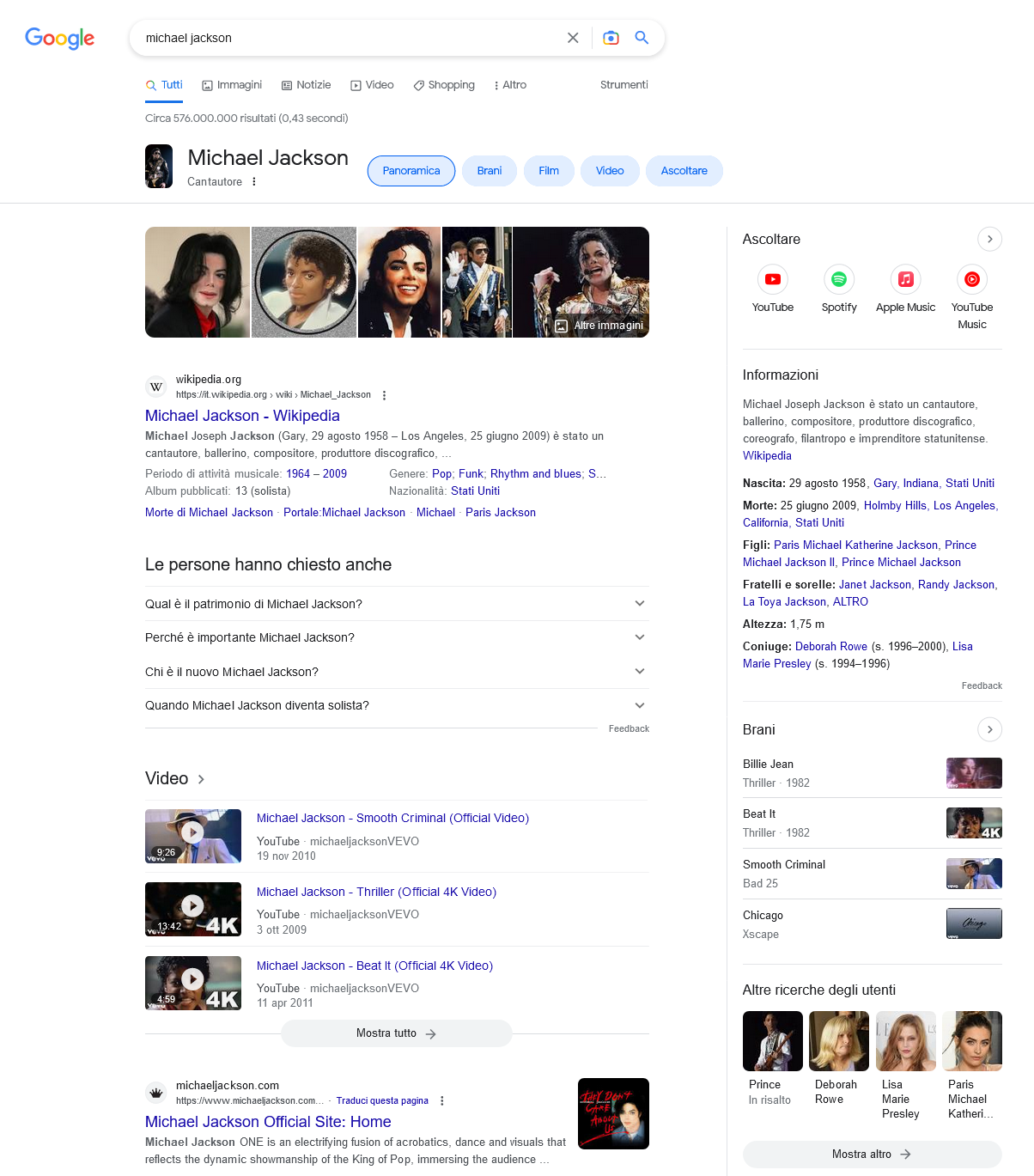
For Google, moreover, the graph is of considerable value because it organizes the world’s information by topic, rather than on the basis of crawling and indexing web pages and websites alone, with advantages and positive effects in terms of scalability, diversity, integrity and speed of information.
Which queries generate the graph?
In the list of entities that can generate a Knowledge Graph as a response are general queries about famous people in history, influential personalities of the present, places, things, companies, businesses, brands, cities, sports teams, products, recipes, books, and so on, but also more specific queries introduced with interrogative pronouns or adverbs (also implied).

As we said, usually this data is shown within a knowledge panel, but it can also help determine which results are linked together in carousels. It all works through the automatic processing of search algorithms, which not only find the information but are also tasked with vigilance to prevent information from appearing that violates Google’s rules. Specifically, no advertisements, dangerous content, content pertaining to deceptive practices, harassing, inciting hatred, medical topics, regulated products, sexually explicit, terrorist in nature, reporting violence and bloodshed or vulgar and blasphemous language, or manipulated media content appear in the Knowledge Graph; what’s more, Knowledge Graph visualizations are subject to two additional specific rules, covering misinformation (that is demonstrably false or outdated based, for example, on legal documents, expert consensus, or other reliable primary sources, or information presented as fact but without supporting evidence, particularly if it accuses individuals or groups of serious malicious acts) and unrepresentative information (i.e., names, titles, descriptions, and images of topics, if supported by solid evidence that Google’s automated systems did not make the most representative choice).
A graph of information and relationships
What is amazing is the system’s ability to link results together and understand precisely what the user wants to say, eliminating or reducing possible misunderstandings or ambiguities in the search, based on experience and consultation of previous data in memory of queries made by the totality of users.
In practice, it is the application of artificial intelligence to build a network of relationships between all the different and possible entities, and from its inception Google’s graph aspired to classify the information available throughout the Web according to a criterion of relationships, precisely. Importantly, it is the entities themselves that can communicate to Google the information they deem most important, using Schema.org structured data and markup, which is a method by which to help Googlebot better understand site content and, again, important SEO signals for ranking.
The resources used for Google’s Knowledge Graph.
The criteria used by Google to include or not include an entity in its graph is not always clear, but instead the resources used to compose Knowledge Graphs are certain; the first one we have just mentioned, which is the Schema.org markup to be filled in for the home page by including all the information that is deemed relevant to the organization, personality or local business.
Another common element is the trust that Google places in Wikipedia, from which it takes both summary descriptions and official site addresses (when not directly communicated): having an entry on the online encyclopedia is therefore crucial to gaining trustworthiness, just as the Wikidata database is also appreciated.
The importance of curating social
The other tools to exploit in order to offer Google reliable information (and to try to impose oneself as an entity) are social profiles and, for businesses, the business profile (formerly Google My Business): in the former case, having identified and verified accounts is a way to be recognized by Google (even when it cannot find the official website), while the free system with the business profile is obviously a preferred route for the information reported in the graph.
The changes that can be suggested to the Knowledge Graph
Each entity can claim its own information box and can, if necessary, request changes from Google; the first step is to obtain recognition as an official representative (usually just accessing a verified profile or the official website through Google) and then using the Suggest a Change option found in the box itself in the SERP. It is good to know, however, that changes are only accepted regarding five aspects, namely featured image, social profiles, title, subtitle and description, plus any statistics specific to the type of entity (e.g., the length of a movie, the schedule of a music festival or a person’s birthday, remembering that not all available statistics appear in the information tab). Modification is then provided for other elements as well, but only in cases of violation of the aforementioned policy rules, and all suggested changes go through a review process to confirm their veracity and exclude inappropriate content, checking that the information is confirmed by other publicly available online sources.
On the other hand, changes to other parts of the Information Box, and specifically to the Wikipedia snippet, the Related Searches section, are also not considered, nor is it possible to request the inclusion of images other than the main image. In addition, Google’s guidance clarifies that “you cannot change the order or hide content if it is correct and in the public domain.”
In addition to the official entities, Google specifies that anyone can submit feedbacks on issues related to fact sheets, activity profiles, or Knowledge Graph information in general: public reports serve to ensure that automated systems work effectively and do not let erroneous or violating content through, and they also help Google implement algorithm improvements.
Knowledge Graph and SEO: how to access the graph and why it could help visibility
Today, Google’s SERPs are full of so many features, boxes and panels that go beyond the old blue links and often, indeed, take away space from organic results and provide users with direct answers without the need to click to read; underlying some of these features are precisely the entities and information present in the Knowledge Graph, which is therefore, so to speak, co-responsible for negative phenomena for SEO such as drop in visits and click-through rates from Search. Moreover, before checking the open web to formulate an answer to a query, Google’s systems will first examine the pre-existing knowledge in the graph, thus reducing traditional organic opportunities even more.
From another perspective, however, appearing in SERPs with a Knowledge Graph tab for one’s brand is a great way to strengthen visibility, gain extra traffic to the site, and help people discover its physical locations (if we are talking about businesses).
In short, SEO practitioners cannot disregard the Knowledge Graph for both the target entity and the broader business context, looking for solutions to get into Google’s database and try to appear in Knowledge Panels. In fact, we should preface this by saying that there is no foolproof way to get a Knowledge Graph panel, because even following all the steps below there is no guarantee that Google will actually decide to enter the entity in the database or, more precisely, to show its information in SERPs.
However, we have seen what official resources Google uses for its graph, so following a few steps represents a potential opportunity to achieve the goal and gain more visibility for your brand, in the form of Knowledge Panel and rich snippets, but also in terms of “trust” gained in the eyes of the search engine.
In particular, following Search Engine Journal‘s suggestions we can:
- Leverage schema markups
Schema markup is invisible to visitors, but it is critical to help the Knowledge Graph gather information about a brand/business: so we need to include all the information we think is relevant, such as organization, person, and local business.
- Staying connected with Google, Wikidata.org and Wikipedia
Most of the information on Google’s Knowledge Graph comes from Wikipedia and Google itself, so it would be crucial to be able to create a Wikipedia page for our business (from which Google will borrow the descriptions used in the fact sheet and sometimes even the official website address). In addition, we can also communicate directly with Google by activating the Google Search Console check and, if appropriate, the Business Profile tab.
- Optimizing the Business Profile and Social Media
Regarding the latter, the former Google My Business tab is a must for local businesses because it increases their visibility and authority; then, in Knowledge Graph function, it might also serve to optimize and regularly use social media accounts to interact with customers, acquire new reviews, and get local mentions.
- Verify social media accounts
Still on the subject of social media and social networks, brand profiles can sometimes become a prime source of information for Google, especially when the official website cannot be traced back; in this sense, having verified profiles (net of the most recent changes to the various ticking systems) can be a plus for being identified by Google as a relevant and pertinent entity and thus gaining inclusion in the Knowledge Graph. One way Google can recognize us as an official brand representative is through the YouTube channel, which gives the ability to request changes to the Knowledge Graph tab.
- Curating content and information
The last-and most general-advice is to always curate the content posted on the site and social (always trying to intercept the quality and usefulness criteria required by Google) and, at the same time, check that the information on the various sources is consistent and accurate. This also includes checking the Knowledge Graph tab that may have been obtained, activating if necessary the process of requesting a change in case of the presence of errors or inaccurate information.
