
Regex, a guide to Regular Expressions and their use in the SEO
They are a true and proper language, apparently complicated but not that difficult to learn, and their use can give us a big support in perfecting the analysis and monitoring of data, even for SEO: we make a focus on Regex or Regular Expressions, the functions that allow you to filter the results, to find out which are the common regex operators, the most useful for SEO and those that we can use in tools such as Google Analytics and Google Search Console.
What are the Regex
The term Regex is an abbreviation of Regular Expression (as well as sometimes you will find references such as regexp or RE): essentially it is a string of symbols that allows you to filter and identify a search pattern, or more precisely a sequence of characters that enables a function to filter, compare or identify character strings or code.
Regular expressions are used in search engines, search dialog boxes and text processor and text editor replacements, text processing utilities and lexical analysis, but also many programming languages provide built-in regex functionalities or through libraries, since the situations of use are multiple.
The most immediate example to understand what Regex are is to think about the function “find” or “find and replace” on Word – which searches for the exact string of characters inside the document and eventually replaces it with the other string you want – or the search function in web browsers (the one that is usually activated by clicking the CTRL+F keys).
The evolution of regular expressions
Although the first formulation and formalization dates back to the 1940s, it was only in the following decade that regexes began to make their way, thanks to the work of American mathematician Stephen Cole Kleene, who described a regular language, and later by Ken Thompson, who used them in the QED editor in 1966, before becoming in common use with the Unix text processing utilities.
However, it was in the 1980s that, thanks to the native Perl programming language, regular expressions became common and since then several regex syntax have been imposed, such as the POSIX standard and the Perl syntax.
Today regex can be used on Javascript, Python and other programming languages, and can become a versatile and powerful SEO tool.
What are the Regex for
Due to their characteristics, regular expressions serve to simplify the search for common data and information within a document or set of resources, specifying precisely the rules that are used to describe the set of possible strings that you want to match to discover search results that, at first glance, may seem to have little in common.
With this tool you can, for example, include complex search strings, partial matches and wildcard characters, perform case-sensitive searches or set other advanced instructions, almost as if it were an online programming language for doing text searches.
Other advantageous aspects of Regex are the validity in every language and regardless of the platform and the great practicality of use, although it must be kept in mind that their language is relatively small and not all string processing activities can be performed this way.
How a Regex looks like
To frighten those who do not know this language is probably the form, which at first glance appears complex: in fact, generally, a regular expression includes a combination of text (which will match exact in the search results), along with several operators that act more as wildcard characters to search for a pattern match.
In practical terms, as Dan Taylor explains in an interesting article, a Regex can include just a single wildcard character, a match for one or more characters or a match for zero or more characters, as well as optional characters, subexpressions nested between brackets and “o” functions. By combining these different operations together, it is possible to construct a complex expression that allows to obtain far-reaching, but very specific results.
More precisely, you can use regular expressions to filter out simple strings (but it is “like hunting for flies with a rocket launcher”, says Giovanni Sacheli), use single characters (the simplest filter, remembering that character is any letter, number, symbol and space), take advantage of the special characters and meta-characters (the characters that have a special meaning), and then again the anchors (which serve to indicate in which position of the text to perform the analysis) and modifiers (which expand or restrict the portion of text to be analyzed).
Common operators of regular expressions
Examples of common regex operators include:
. (fullstop) is a wildcard character, can therefore represent each individual character
* (asterisk) selects a match for zero or more items.
+ (plus sign) selects a match for one or more items.
? (question mark) makes the previous character an optional part of the expression
digit o d sets a match for each digit 0-9
| (pipe, vertical line) means an opposite function (OR).
^ (circumflex accent) is used to denote the beginning of a string.
$ (dollar symbol) is used to denote the end of a string.
( ) (round brackets) are used to nest a sub-expression.
(backslash) if inserted before an operator or a special character is intended as “escape”, it basically allows to exclude a special character.
Some programming languages, such as Javascript, also allow the inclusion of flags after the regex pattern itself, which can further influence the result, such as:
g returns all matches instead of just the first one.
i returns results without distinction between upper and lower case.
m activates the multi-line mode.
s activates the “All” mode.
u activates full Unicode support.
y looks for the position of the specific text (“sticky” mode).
The combined use of these operators and flags allows to create a complex logical language and offers the possibility to obtain very specific results on large and not ordered datasets. It should also be remembered that depending on the programming language we are using, the engine that makes regular expressions work can change, and this affects the way the main commands (which remain identical) are applied.
Regex and SEO, how to take advantage of regular expressions
As a rule, regexes are useful to avoid any kind of repetitive work, automating some functions to save time and effort.
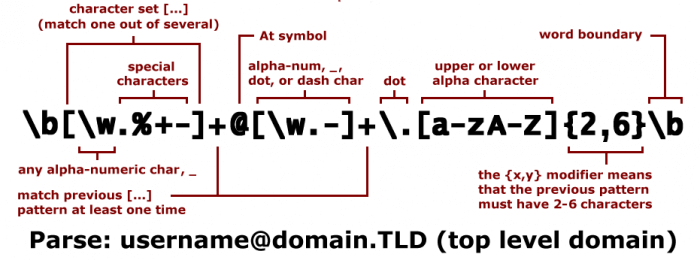
Among the possible applications of Regex there is the redirection of a set of pages, the URL rewriting on web server Apache or the validation of the format of an e-mail inserted in a form. By definition, in fact, e-mail addresses must be composed in this way: begin with a sequence of alphanumeric characters and special characters, followed by the spiral symbol, followed by other alphanumeric characters, followed by the point, followed by two or three letters: codifying this informal rule in a regex we get this result,
^[_A-Za-z0-9-\+]+(\.[_A-Za-z0-9-]+)*@[A-Za-z0-9-]+(\.[A-Za-z0-9]+)*(\.[A-Za-z]{2,})$
or
^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+.[a-zA-Z0-9-.]+$
Regular expressions can therefore also help us in areas far from those of textual analysis and in recent years they are also finding space in the SEO, in particular to redirect 301 within the . htaccess file or to take control of your data and filter the less useful parts of it for the analysis of returns, such as limiting traffic sources to a single source, specific medium or geographical area of reference, or to explore the queries used by different segments of users, identify the queries common to specific areas of content, searches that direct traffic to specific parts of the site and more.
In all these cases we can create regex expressions that are simple enough to get a basic “include” or “exclude” filter, or write longer expressions that work in a similar way to the programming code to get complex and very specific results: familiarizing with this tool helps us to verify that SEO efforts are reaching the goals, ambitions and achievements we had in mind.
How to use Regex in Google Analytics
One of the most common uses of regex for SEO is in Google Analytics, where regular expressions can be used to set filters that allow you to view only the data we are interested in. In this sense, the expression is used to exclude results, rather than to generate a set of inclusive search results.
In particular, you can exclude from reports the traffic within the company or local network, by setting the 192.168 filter. *. * to remove the entire range from 192.168.0.0 to 192.168.255.255, and in combination with Regex expressions we can filter any range of IP with just one string.
Still, another useful feature is that of the advanced segments, which can serve to split non-branded keywords so that you can specifically analyze the results of specific SEO activities – the Regex in this case must exclude all branded keywords, in possible variants – or to filter traffic from social networks.
In his article, Taylor suggests specific example of more complex usage of regular expressions in Google Analytics, based on the two trademarks regex247 and regex365: if we want to filter the results that match any combination of Urls that contain these brand names, such as regex247.biz or www.regex365.org, we can set a basic alternative expression, which is
.*regex247.*|.*regex365.*
that allows you to exclude from Analytics data all the corresponding Urls, including subfolder paths and specific page Urls that appear on those domain names.
From a practical point of view, before creating a regex filter on Google Analytics you need to set the type of ratio you want (e.g. Behavior > Site content > All pages or Acquisition > All traffic > Source/ Medium); to view the advanced filter options we need to click Advanced next to the search box that appears below the chart at the top of the data table.
Here we can include or exclude data based on a certain size or metric: in the dropdown list, after selecting the size, we choose “with espr. reg” (Matching Regexp) and then insert the expression into the text box.
To create an “or” alternative expression in Google Analytics, it is sufficient to include the pipe character (the vertical tract symbol |) among the appropriate segments of the expression. Google Analytics regular expressions do not support “and” instructions within a single regular expression, but we can still add another filter to achieve the same effect.
In particular, just enter another regex under the first one by clicking “Add a size or metric” and adding all the useful expressions, which will be processed as a single logical instruction “and” when filtering data.
Practical advice for Regex in Google Analytics
Taylor also clarifies some aspects about the use of regular expressions in Analytics, noting first that a function “badly written can easily filter most or all data, including a match with unlimited wildcard characters”.
The good news is that, in many cases SEO, the filter is applied to the data only during reporting and therefore, by modifying or eliminating the regular expression, it is easy to restore the full visibility of the data.
To avoid problems, however, it is best to test regular expressions on a set of online test tools, in order to see if they get the expected result, by running the “sandbox” of the regex before leaving them free in the entire data set.
How to use Regex in Google Search Console
Since last April 2021, Google has also introduced the use of Regex in the Search Console, starting support for Re2 syntax to allow webmasters to include and exclude data within the user interface, also including in June 2021 the extension to negative regex, which gives all information filtered by correspondence excluded.
Among the notes of use of the Regex in Search Console there is the limit of characters for the function – 4096 characters, usually sufficient length to the analysis needs – as well as a specific syntax, clarified by this document on Github.
Regex in Search Console can be used to filter queries containing a specific brand and variations that users might type: for example, for Facebook you could use variants (including spelling errors)
.*facebook. *|face*book. *|fb. *|fbook. *|f*book. *
that also help segment users who already know the brand. Another useful use is filtering users who find the site through terms of commercial intent, such as
.*(best|top|alternative|vs|against|review*). *
More analytically, Regex can help us to verify the amount and type of traffic to a section of the website and to understand the intent of users, as suggested by a Google guide.
In the first case, we can use a regex that focuses on site-specific directories, so as to understand what are the common queries for each of the content areas. For example, the document says, “if the structure of the URL is example.com/[product]/[brand]/[size]/[color] and you want to display the traffic to the green shoes, but you are not interested in the brand or number, you can use shoes/. */green”. A regular expression can also serve to analyze the types of queries that lead users to different sections of the website: for example, “you may be interested in queries containing words that introduce a question; a query filter what|how|when|why could show results that indicate that your content should easily answer questions, perhaps via a frequently asked question section.”, while with other filters we can “check what are the names of the products used more often or less rarely”.
