
Who are the Google quality raters and what guidelines they follow
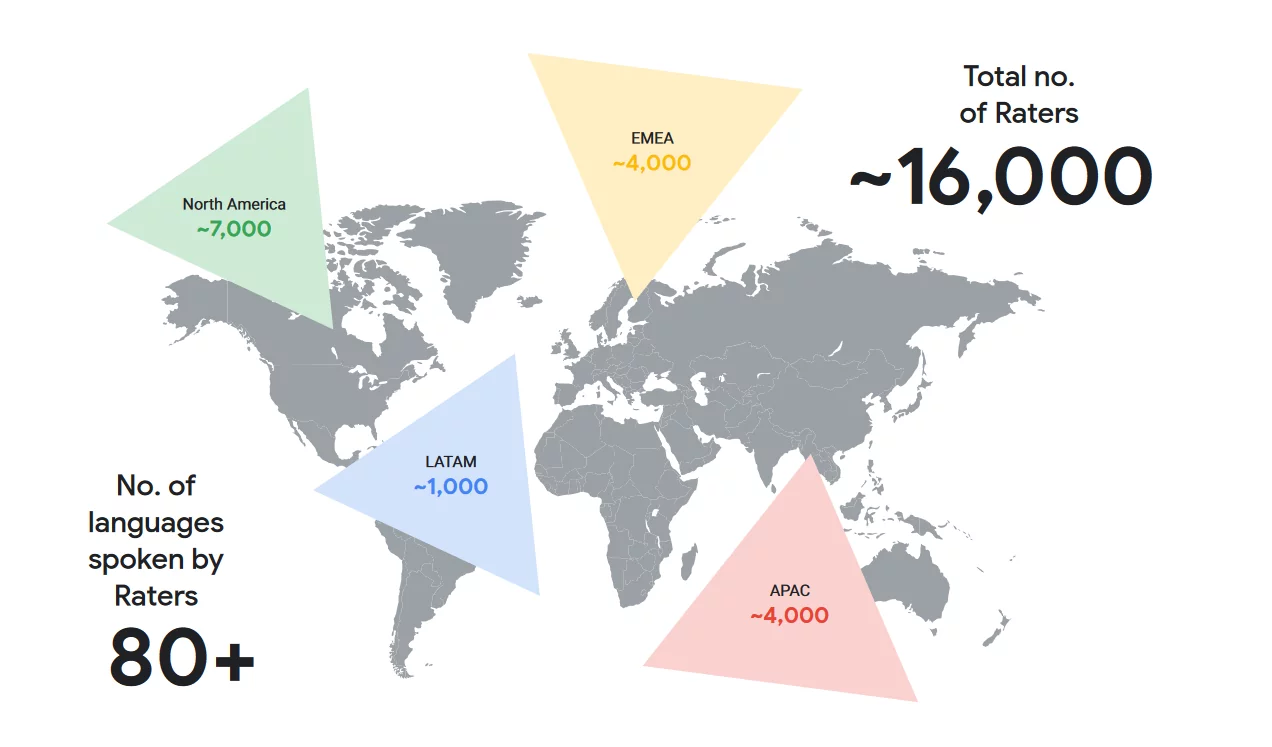
A team of over 16 thousand people, active worldwide and engaged in a specific task: evaluate the results provided by Google in the light of the guidelines provided by the company, to find out whether the SERPs actually meet the criteria reported and whether, therefore, users receive an effective and positive service. Today we try to find out more about Google Quality Raters and the documents they must refer to, to understand what they really do, debunk some myths and, no less importantly, understand how their work affects Research and what you need to know about the concept of EEAT.
Who are the Google Quality Raters
It was at least the 2005 when Google launched the quality raters program, involving a small army of testers, evaluators and quality reviewers in the evaluation work of its final product, namely the SERPs shown to the public, the pages containing the search results.
After several years of rumors and speculation, in August 2022 the company drafted an official document (periodically updated) explaining who these figures are and how they work, confirming that it indirectly employs about 16 thousand quality raters worldwide, paid per hour (13.5 dollars, it seems), through a network of contracting companies. These external Google employees are hired through term and temporary employment contracts, which can be renewed but generally never last very long.
These people are the driving force behind the “Search Quality Rating Process“, which precisely measures the quality of Search results on an ongoing basis through the efforts of the 16,000 external Quality Raters, who provide ratings based on special guidelines and “represent real users and their likely information needs, using their judgment to represent their locality,” as clarified by Google.
How can one becomes a google evaluator?
There is obviously a good deal of secrecy around this program, and there is no way to submit your quality rater application or an office or email to which you can send a resume: as far as you can expect, it is Google that directly contacts the people it identifies as potential evaluators considering them up to the task (sometimes bloggers scattered around the world), or delegates in subcontract the search to specialized agencies.
The short duration of the contracts has a very specific ratio: it prevents the quality raters from being able to interfere in some way with the research system going beyond their duties or to take advantage of their position.
Over these 17 years, Google’s program has employed millions of QRs, who have been the external, human eyes to watch over the quality of SERPs and the results provided.
Stepping out of the realm of speculation, Google has (finally) specified who the Quality Raters actually are, 14 thousand people distributed in various parts of the world (as seen in the map, about 400 are those employed for the EMEA area, which includes Europe, the Middle East and Africa) who represent Search users in their local area, so as to ensure the fundamental diversity of locations and efficiency in different areas.
The U.S. company admitted that recruiting is outsourced and the actual number of QRs may vary according to operational needs.
The characteristics required for the job are “a high familiarity with the language of the task and the place, to represent the experience of local people” but also an understandable “familiarity and familiarity with the use of a search engine.”
As for the employer’s other requirements, then, evaluations must not be based on the raters’ personal opinions, preferences, religious beliefs, or political views (as also enshrined in the December 2019 update of Google’s guidelines for quality raters), who are required to “always use their best judgment and represent the cultural standards of their country and place of evaluation.” In addition, to actually get the job, potential raters must pass a test on the guidelines, which is used to ensure that Google’s quality standards are met.
The duties and functions of Google Quality Raters
So, what do these Google evalutors do? We can think of them as a group of quality auditors, who evaluate a company’s results on the basis of criteria, principles and documents provided by management.
In the case of the search engine, GQRs are in charge of analyzing and studying the information contained in the query results using the famous Google guidelines, the General Guidelines of the Search Quality Rating Program that are published online, publicly available and constantly updated – the most recent version was published in November 2023.
Google quality raters do not determine penalties, downgrades or bans
It is good to immediately clarify one aspect: Google’s project contributors have no access or control to any component of its algorithms and do not directly determine penalties, bans or drop of rankings for sites.
Their function is not to decide the positions of the results in SERP, but only to verify that the product – that is to say the search algorithm – is working in the expected way and according to the established rules.
That said, with their judgment the quality raters can still indirectly influence the organic positioning of the pages, as they analyze the quality of the contents and assign a human assessment that will then be interpreted and elaborated by the appropriate Google teams.
If we want to summarize it, we can say that they do not influence the ranking of the sites they evaluate, but they influence the rankings of each site compared to the queries being evaluated. In Google’s words, quality raters work based on a common set of guidelines and are given specific tasks to complete. Aggregate ratings are used by Google to measure how well its systems are working to provide useful content around the world; in addition, ratings are used to improve these systems by providing them with positive and negative examples of search results.
A support for machine learning training as well
As expert Marie Haynes, who has studied the topic at length, notes, Google raters are an important piece of the ranking puzzle through which we can discover more about the inner workings of Google‘s search algorithm, which of course remain shrouded in secrecy.
Specifically, in addition to the “known” tasks, Haynes suggests that Google uses the ratings of its quality raters to provide machine learning systems with examples of useful and not-so-useful search results, particularly after the debut of Helpful Content system.
In fact, until last year Google had explicitly denied that QR data was used to train its machine learning classification algorithms, but there are signs that this choice has changed in recent years.
For example, as of 2021, Google’s page on how Search works explains that machine learning is used in their ranking systems:
In addition to keywords, our systems also analyze whether content is relevant to a query in other ways. We also use aggregated, anonymized data on interactions to assess which search results are relevant to searches. We turn that data into indicators that help our machine learning systems better assess relevance.
Even more starkly, then, as of 2022, the QR guidelines clarify that ratings are used to measure the performance of search engine algorithms and “also to improve search engines by providing examples of useful and not-useful results for different searches” or “positive and negative examples of search results.”
Such labels of “useful” or “unhelpful” results are valuable to Google’s machine learning algorithms: by classifying search results as “useful” or “unhelpful,” the quality evaluators provide real human feedback from which the algorithms can learn.
How human evaluation work on the quality of results in SERPs works
Each quality rater has the task of verifying the quality of a group of Serps and then controls a series of web pages (usually, those best placed for the most delicate queries); its task is to judge, based on a precise check-list, if the document complies with the guidelines on the informative and technical quality of the pages.
Once completed this review, the quality rater assigns a quality rating, on a minimum to maximum rating scale: it is not a subjective or personal assessment, but the margin of discretion is very limited and the reviewer must strictly comply with the aforementioned guidelines drawn up by Google. These data are then provided to machine learning systems, which use them to improve algorithms based on known factors.
Thanks to this work, Google can identify disinformation elements that can escape automated algorithmic systems. The mission of quality raters is therefore to contribute, through a human judgement, to make the pages of research results useful and high quality, reducing the presence of misleading results and content not up to the standards.
More specifically, aggregated ratings are used to measure the level of efficiency of Google’s systems in delivering useful content around the world, and are also used to improve those systems by providing positive and negative examples of search results.
Rater Task: what is the process behind the ratings
From this perspective, it is again the Big G document that clarifies how the standard evaluation process (referred to as the Rater Task) works: first, Google generates a sample of searches (e.g., a few hundred) to analyze a particular type of search or a potential change in rankings. A group of raters is assigned this set of searches, on which they are to perform certain tasks: for example, one type of task is the side-by-side experiment, in which raters are shown two different sets of search results, one with the proposed change already implemented and one without, to indicate which results they prefer and why.
In addition, raters also provide valuable feedback on other systems, such as spelling. To evaluate proposed improvements to the spelling system, Google asks raters whether the original query is misspelled and whether the correction generated by the improved spelling system is accurate for individual queries.
Raters also examine each page listed in the result set and rate it according to rating scales established in the appropriate guidelines for raters; the search quality assessment consists of two parts, as seen in this image.
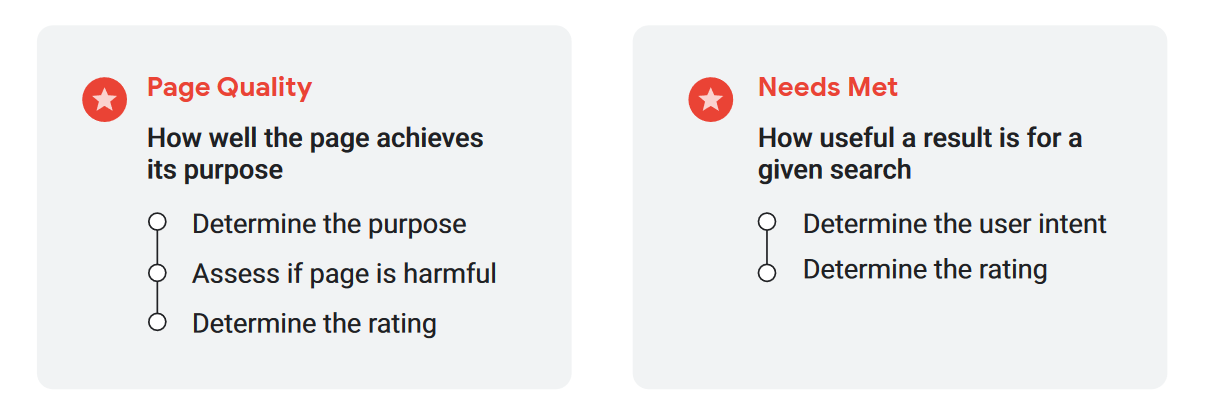
On the one hand, there is the focus on “Page Quality” – which seeks to determine how well the page achieves its purpose through analysis of the purpose itself, evaluations on possible risks of the content, and definition of the rating-and on the other hand, there is the focus on “Needs Met” or satisfaction of user needs, which refers to how useful a result is for a given search through determination of the search intent (user intent) and its overall rating.
Again, it is openly reiterated that “no single rating-or single evaluator – directly affects the ranking of a given page or site in the Search.” Not least because, the paper adds, “with trillions of pages constantly changing, there is no way that humans could rate each page recursively,” and therefore simply using Search Quality Ratings for ranking would not be feasible, “since humans could never rate each page on the web individually.”
In addition to being an impossible task, using only Search Quality Ratings to determine ranking would not provide sufficient signals to determine how the ranking itself should work, and there are “so many dimensions of quality and relevance that are critical, such as signals that indicate something might be spam, signal that a site might be dangerous or unsafe, or indicate that a page might be out of date.”
Therefore, the paper concludes, “no single source of information, such as an assessment of search quality, will or could ever capture all the dimensions important to a task as complex as ranking.”
The evaluation process: Google’s guidance on page quality
As mentioned, the first phase of the quality raters’ work focuses on identifying and evaluating Page Quality, i.e., the quality of the page they are asked to comment on.
The goal of the PQ rating process is to assess how well the page actually achieves its purpose and is divided into three steps:
- Determining the purpose
To assign a rating, evaluators must first understand the purpose of the page: for example, the purpose of a news site homepage is to inform users about recent or important events, and so on for all possible types of pages and sites. This allows evaluators to better understand what criteria are important to evaluate the quality of that page in Step 3.
Google also makes it clear that since there are different types of sites and web pages that may have very different purposes, its “expectations and standards for different types of pages are also different.”

Another very interesting point is reiterated in the document: for Google, sites and web pages should be created to help people (and when they fail to do so, a Low quality rating is justified and appropriate). When pages are useful and are created to help people, Google makes no quality distinction between one particular purpose or type of page and another: put another way, encyclopedia pages are not necessarily of higher quality than humorous pages, as long as they all help the user.
There are high and low quality web pages of all different types and purposes, such as “shopping pages, news pages, forum pages, video pages, pages with error messages, PDFs, images, gossip pages, humor pages, homepages, and all other types of pages,” and “the type of page does not determine the PQ rating,” which is instead determined only by understanding the purpose of the page itself.
2. Evaluation on whether the purpose is dangerous
In the second step of the process, quality raters are asked to ascertain whether the purpose of the page is harmful or whether the page has the potential to harm and cause harm.
If the site or page has a harmful purpose or is designed to deceive people about its true purpose, it should be immediately classified as lowest quality relative to the FP. They are of lowest quality, for example, websites or pages that are harmful to people or society, unreliable or spammy, as specified in the guidelines. However, Google explains that there is “a lot of content on the Web that some people might find controversial, unbiased, distasteful, or in bad taste, but that is not to be considered harmful” under the requirements identified by Google.
3. Establishing the rating
The last step is the actual determination of the rating and, therefore, the PQ rating, which is based on the page’s ability to achieve its purpose on a scale ranging from Lowest to Highest quality.

The main criterion for the page quality rating is to refer to the page’s E-E-A-T parameters, that is, the levels of experience, expertise, authority, and trustworthiness it communicates. Specifically, quality raters must consider and evaluate:
- The first-hand experience of the content creator.
- The creator’s expertise.
- The authority of the creator, the main content and the website.
- The trustworthiness of the creator, the main content, and the website.
Specifically, the official document explains that QRs determine the Page Quality rating through:
- Examination of the quantity and quality of Main Content. As a general rule, Main Content is of high quality if it requires a significant amount of effort, originality, and talent or skill to create.
- Examination of the information available about the website and its creator: it should be clear who is responsible for the website and who created the content on the page, even if they use pseudonyms, aliases, or usernames.
- Research the reputation of the website and creator. The reputation of a website is based on the experience of real users and the opinion of people who are experts in the topic covered by the site.
Speaking of topic, then, here Google explicitly refers to pages with YMYL or Your Money, Your Life content, which require different quality standards than others because they could “have a significant impact on people’s health, financial stability or safety, or the well-being of society.”
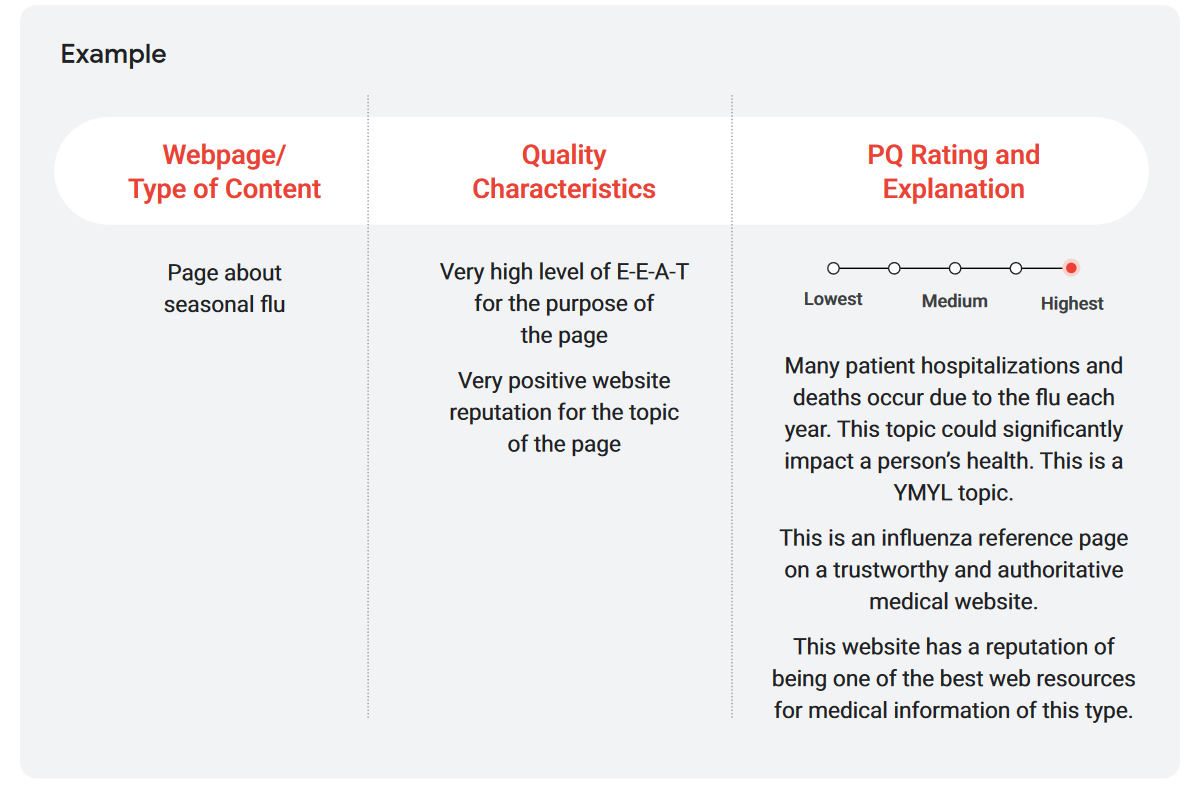
Raters are required to apply very high PQ standards for pages on YMYL topics because low-quality pages could have a negative impact on people’s health, financial stability or security, or the well-being of society. Similarly they should receive the lowest rating, other websites or pages that are harmful to people or society, unreliable, or spammy.
Needs Met rating, the degree of user satisfaction
The second, big, task of Google Quality Raters is the Needs Met rating, in which they have to focus on user needs and the usefulness of the result for people using Google Search.
The usefulness of a search result concerns the user’s intent or search intent, as interpreted by the query, and the degree to which that intent is satisfied (how well the result fully satisfies that intent).
Thus, there are two steps for the assessment of satisfied needs:
- Determination of user intent from the query
A query is “the text, image and/or other content that a user enters into the search box of a search engine or search application to perform a search” and can “be spoken, typed, copied and pasted, come directly from a camera or other application and/or be related searches that appear in search results,” says Google, which explains that it uses “query content and, if relevant, the user’s location to determine intent.”
For example, if a user searches for “coffee shops” and resides in London, the search engine may determine that their intent is to find “coffee shops” in the English capital. However, many queries also have more than one meaning: for example, the term “mercury” might tie into the intent to learn more about the planet Mercury or the chemical element.
Google assumes that “users are searching for current information on a topic, and evaluators are instructed to think about the current meaning of the query as they evaluate”-and so effectively the time factor and freshness have value and weight.
Another aspect updated in 2023 is Google’s own precise definition of what it means by “query interpretations,” or the possible meaning-or more frequently the possible and various meanings-of a query or what the query might refer to. Many queries can in fact have more than one meaning, and for example (in English, but not only) the query [apple] could refer to the computer brand or the fruit or something else.

Thus, from this assessment comes the identification of 4 categories of interpretation probability:
- Dominant interpretation. The dominant interpretation of a query is what most users mean when they type the query. Not all queries have a dominant interpretation. The dominant interpretation should be clear, especially after doing a brief web search.
- Common interpretation. A common interpretation of a query is what many or some users mean when they type a query. A query can have multiple common interpretations.
- Minor interpretation. Sometimes less common interpretations can be found, those that fewer users have in mind. They are divided into.
– Reasonable minor interpretations. Reasonable minor interpretations may be useful to fewer users, but they are still useful to have in a result set because different users may want different things.
– Unlikely minor interpretations. An improbable minor interpretation is one that is theoretically possible but very unlikely-it is very rare for users to have it in mind. - Unlikely interpretation. An interpretation so unlikely that almost no users would have it in mind. Results for interpretations without possibilities seem off-topic even if they match the words in the query. For example, almost no one wants a result regarding an overheated pet for the query in American English [hot dog].
As Lily Ray explains, minor interpretations are essentially “meanings that are less likely to be the commonly expected meanings of the query,” and the next distinction clarifies that “Reasonable minor interpretations” are those that help “fewer users” but are still useful for search results, while “Unlikely minor interpretations” are theoretically possible but highly unlikely.
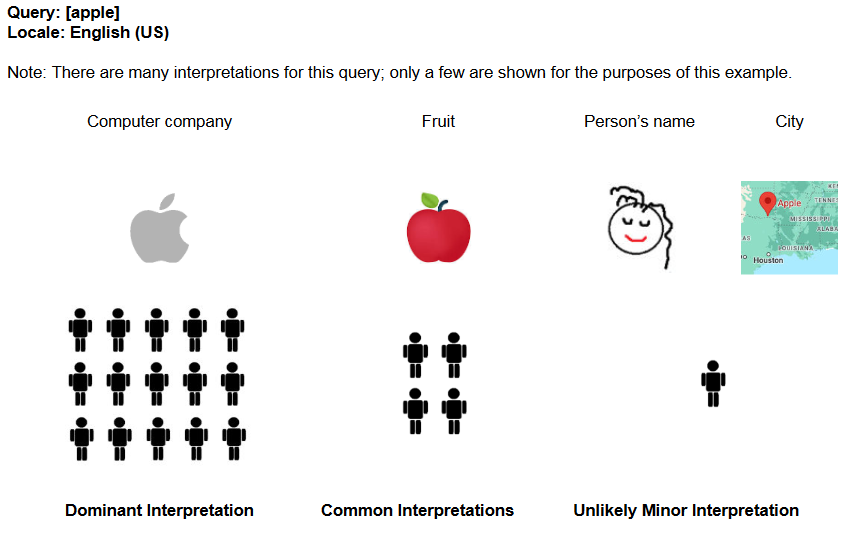
Google has also added some new visual examples of how to interpret these definitions: for example, a “likely minor interpretation” of the search query [Apple] would be the person’s name or the U.S. city, Apple, Oklahoma; for [Mercury], on the other hand, it is considered unlikely that many people would be interested in the British airplane designed during World War II.

2. Determining the rating
The second step is the specific Needs Met rating of the page, which is based on how well a search result responds to the user’s intent – one more focus changed in 2023.
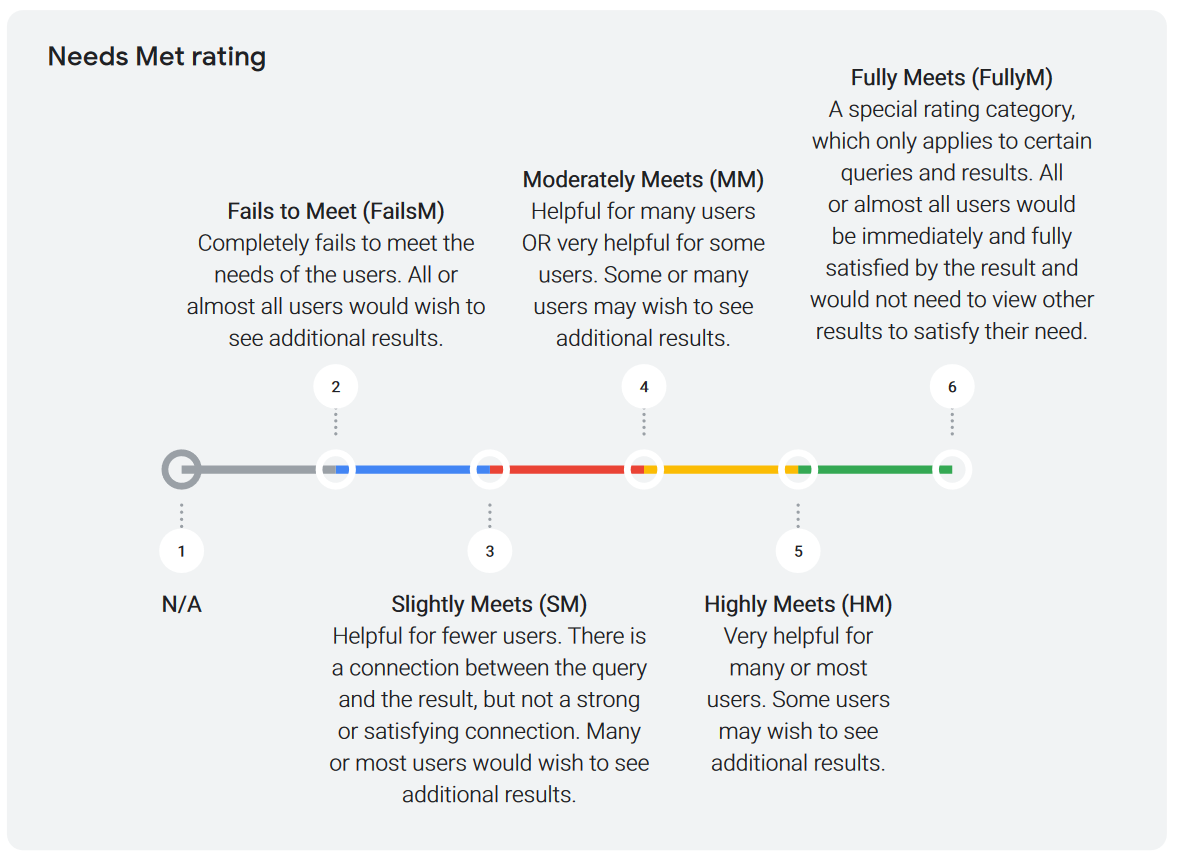
For evaluation, these directions apply:
- Fails to Meet (FailsM) should be assigned to a result that completely fails to intercept the needs of all or most users. For example, the result might be off-topic for the query or might respond to an interpretation of the query that is practically impossible.
- Slightly Meets (SM) should be assigned to a result that may be of little help for a prevailing, common, or reasonably secondary interpretation of the user’s intent, or to a result that may be helpful but for an interpretation of the user’s intent or the query that is rather rare or unlikely.
- Moderately Meets (MM) should be assigned to a result that is useful for any main, common, or reasonably secondary interpretation of the user’s intent or query.
- Highly Meets (HM) should be assigned to a result that is very useful for any main, common, or reasonably secondary interpretation of the user’s intent or query.
- Fully Meets (FullyM) is a special evaluation category, which applies only to queries with a clear intent to find a specific result and the corresponding specific result the user is looking for. These are, in most cases, navigational queries or queries with a very specific request (finding an address, knowing certain information, and so on), which have no ambiguity of interpretation.
In determining the rating, the Quality Rater must consider the extent to which the result:
- “fits” the query;
- Is up-to-date;
- Is accurate and reliable for inquiries;
- satisfies the user.
According to these criteria, a result rated as “fully meets” means that a user would be immediately and fully satisfied with the result and would not need to view other results to satisfy their needs. In contrast, the screen below shows a case of satisfaction failure, because it is “extremely unlikely that [the person who launched] this query is looking for information about a city in Turkey called Batman, since the user is located in the United States. No user or almost no user would be satisfied with this result.”

Google’s guidelines for quality rater
At the heart of this important activity, then, are the instructions contained in the Search Quality Rater Guidelines, a document with more than 150 pages at its latest version that plumbs all that quality means to Google, offering guidance to QRs (but really anyone, since it is accessible and public) on how to carry out their work. Specifically, evaluate the results of sample queries and assess the extent to which the pages listed seem to demonstrate characteristics of reliability and usefulness.
As we read at the beginning of the document, “the general guidelines concern mainly the evaluation of the quality of the page (PQ) and the assessment of the needs (NM)”: in practice, the quality raters have the task of expressing an opinion and a vote on the way in which the search engine responds to search intent (needs) and required quality levels.
The interpretation of the usefulness of results
In a recent study of Searchenginejournal, Dave Davies gives us some useful information about the work of quality raters and in particular about the evaluation process, which is probably based on the question “How useful and satisfactory is this result?”.
During the test, an evaluator can visit a single web page or focus on an entire SERP, analyzing each result placed. In both cases, it will send signals to Google about the structure of the site, the device, demographic differences and location results, plus a number of other factors that apply to the classification of each result.
These data will guide changes to improve results and algorithmically determine which factors or combinations of factors are common to results with higher rankings. The evaluation of needs met requires at least decent page quality and is based on both the query and the result.
Human work is also useful in the interpretation of ambiguous queries, such as those that have multiple results: in these cases, the NM score must give more weight to the pages that satisfy the highest and most sought-after intents, so as to prevent the high positioning of pages dealing with topics that do not correspond to the general search intent and the sending of wrong signals to algorithms, which therefore can focus on the right signals for most users.
The evaluations of the page quality
In fact, and as it was easy to guess, the indications to assess the quality of the pages provided to human testers do not differ much from the best practices that classically refers to the sites: the evaluations are based on a series of factors, all linked to each other, and the weight attributed to each factor is based on the type of site and queries.
There are some types of topics and categories that are under a special magnifying glass, and in particular the most thoughtful one is the sector Your Money or Your Life (YMYL) that, Google’s word, “potentially affects a person’s future happiness, health, financial stability or security”. In this case, raters need to take more care and are advised to give more weight to the EAT.
The division of the site’s contents
According to the guidelines, the sections of a website can be classified into three main categories:
- Main content (MC): any part of the page that directly helps the page achieve their purpose.
- Supplemental content (SC): additional content that contributes to the user’s good experience on the page, but does not directly help the page to achieve its purpose. The example provided by the document are navigation links: an essential element for the site, but not necessary to meet the needs of visitors.
- Advertisements (Ads): Advertising or monetization are content and/or links that are displayed on page for the purpose of monetizing, or receiving money. The presence or absence of ads is not in itself a reason for a high or low quality rating: without advertising and monetization, some web pages could not exist, because maintaining a website and creating high quality content requires even very high costs.
The ease of access and the volume of the main content do their part in the calculations on the quality of the page: it is what helps the rater to evaluate not only if the needs/ intent are met, but also if and how easy it is to access the additional content, if you wish to.
The focus on the E-E-A-T
The section on the EEAT paradigm (formerly known as E-A-T, minus the E for experience) is one of the most complex and discussed, and even Googlers have often stepped in to provide clarification and guidance on these parameters.
The first point to understand is that Experience, Expertise, Authoritativeness, Trustworthiness, EEAT acronyms are not ranking factors on Google.
They are the parameters that quality raters look for and use to guide them in evaluating Web sites and to understand whether Google’s systems work well in providing good information, but they are not part of any algorithm.
So the way it works is as follows: raters use EEAT principles to judge Web sites, and Google uses their ratings to adjust its algorithm. Then, eventually the algorithm will align with EEAT principles, which can be useful to us as a guiding principle in site design, content creation, and support for external signals.
There is no specific optimization we can do for these parameters, but we can still work to improve the (complex) way Google sees, interprets, and evaluates our site and pages and, therefore, to improve the EAT of our content, for example, by working on some signals we can provide to the search engine.
However, the weight of EEAT depends on the type of topic covered, and the guidelines make it clear that, depending on the topic, either first-hand experience (less formal, so to speak) or structured expertise should be ensured: The former includes, for example, extremely detailed and useful reviews of products or restaurants, the sharing of tips and life experiences on forums, blogs, and so on, and all content written by ordinary people who have, however, experienced the situation directly and can therefore be considered experts in such topics without the person/page/website scoring lower for not having “formal” education or training in the field.
Google also makes it clear that it is possible to have shared expertise on YMYL topics: for example, there are forums and support pages for people with specific diseases, and sharing personal experiences is a form of shared expertise; at the same time, however, specific medical information and advice (and thus not simply descriptions of life experiences) should come from physicians or other health professionals with proven expertise.
Ultimately, we can say that the standard of expertise depends on the topic of the page, and to understand this we should ask what kind of expertise is needed for the page to achieve its purpose well.
Google: quality raters improve Search without affecting ranking
This issue remains controversial and has generated controversy and outright frontal attacks over time (such as that of the Wall Street Journal in November 2019), to the point that even Danny Sullivan, Google’s public voice, signed an article explaining how Search ranking changes are implemented, focusing particularly on the role of Google’s quality raters in this process.
A constantly evolving search system to always improve
“Every search you do on Google is one of billions we receive that day,” begins Mountain View’s Public Liaison for Search, who reminds how “in less than half a second, our systems sort through hundreds of billions of Web pages to try to find the most relevant and useful results available.”
But this system cannot be static, we know, not least because “people’s Web and information needs continue to change,” and so Google makes “many improvements to our search algorithms to keep up,” at the rate of thousands per year (such as the 3200 changes in 2018 alone or the 5150 in 2021, for example), with the goal of “always working on new ways to make our results more useful, whether it’s a new feature or offering new ways to understand language to search” (this is the explicit case with Google BERT).
These improvements are approved at the end of a precise and rigorous evaluation process, designed so that people around the world “continue to find Google useful for everything they are searching for.” And Sullivan points out that there are some “ways in which insights and feedback from people around the world help improve search.”
Google search team’s duty
In general, Google works to make it easier for people to find useful information, but the breadth of the audience also determines that users have different information needs depending on their interests, the language they speak, and their location in the world.
Thus, the basic mission is to make information universally accessible and useful, and this is helped by Google’s specific research team (research team) whose job is to connect with people around the world to understand how Search (capitalized, in the sense of Search) can be most useful. People are invited to provide feedback on different iterations of projects, or it is the research team itself that does field research to understand how users in different communities access online information.
The example of Google Go: insights to meet needs
Sullivan also recounts a concrete example: “over the years we have learned the unique needs and technical limitations that people in emerging markets have when accessing information online,” and this led to the development of Google Go, “a lightweight search app that works well with less powerful phones and less reliable connections.” On the same app, Google later introduced “extraordinarily useful features, including one that allows people to listen to web pages aloud, particularly useful for people learning a new language or who may be uncomfortable with reading long texts,” which would not have been developed without the right insights from the people who eventually use them.
Commitment to quality results
Hand in hand with this is the constant work on the actual functioning of the search engine and the quality of the results proposed to users. As the Googler says, “a key part of our evaluation process is getting feedback from everyday users on whether our ranking systems and proposed improvements are working well.”
That is, that SERPs bring out quality content, as explained in detail in the Search Quality Rating Guidelines (currently more than 160 pages long), the meaning of which can be summarized by saying that “Search is designed to return relevant results from the most reliable sources available.”
To determine certain parings, Google’s systems automatically use “signals from the Web itself-for example, where on Web pages the words in your search appear or how pages link together on the Web-to figure out what information is related to your query and whether it is information that people tend to trust.” However, notions of relevance and trustworthiness “are ultimately human judgments, so in order to measure whether our systems are actually understanding them correctly, we need to gather insights and guidance from people.”
Who search quality raters sre
That’s the job of the search quality raters, a “group of more than 10,000 people around the world” who help Google “measure how people are likely to engage with our results.” These external contributors and observers “provide ratings based on our guidelines and represent real users and their likely information needs, using their best judgment to represent their locality.” These people, Sullivan specifies, “study and are tested on our guidelines before they can begin providing evaluations.”
How an assessment works
The article on The Keyword blog also describes the standard process of evaluating quality raters, in a shortened and simplified version of the one above (but it is also interesting to read it to “discover the differences”).
Google generates “a sample of queries (say, a few hundred), which it assigns to a set of raters, who are shown two different versions of the results pages for those searches [a sort of A/B test, basically]. One set of results comes from the current version of Google and the other set comes from an improvement we are considering.”
Raters “review each page listed in the result set and evaluate that page against the query,” referring to the guidance in the aforementioned guidelines, and in particular “determine whether those pages meet the information needs based on their understanding of what that query was looking for” (i.e., whether they meet the search intent) and “take into account elements such as how authoritative and reliable that source seems to be on the topic in the query.”
The analyses on the EEAT paradigm
To assess “parameters such as expertise, authoritativeness, and trustworthiness, raters are asked to do reputational research on sources,” and Sullivan offers an additional example to simplify this work.
“Imagine the query is carrot cake recipe: the result set may include articles from recipe sites, food magazines, food brands, and perhaps blogs. To determine whether a web page meets information needs, an evaluator can consider how easy the cooking instructions are to understand, how useful the recipe is in terms of visual instructions and images, and whether there are other useful features on the site, such as a tool to create a shopping list or an automatic calculator to change the servings.”
At the same time, “to figure out if the author has relevant experience, a rater will do some online research to see if the author has qualifications in cooking, if he or she has profiles or references on other food-themed Web sites, or has produced other quality content that has gotten positive reviews or ratings on recipe sites.”
The underlying goal of this search operation is “to answer questions such as, is this page trustworthy and from a site or author with a good reputation?”
Ratings are not used for ranking
After the evaluators have done this research, they then provide a quality score for each page. At this point, Sullivan strongly emphasizes that “this rating does not directly affect the ranking of this page or site in search,” thus reiterating that the work of quality raters has no bearing on ranking.
Moreover, “no one is deciding that a particular source is authoritative or trustworthy,” and “pages are not assigned ratings as a way of determining how well they rank.” And it couldn’t be otherwise, Sullivan says, because for us this “would be an impossible task and especially a poor signal to use: with hundreds of billions of pages constantly changing, there is no way humans can rate each page on a recurring basis.”
Instead, ranking is composed of “a data point that, taken in aggregate, helps us measure the effectiveness of our systems to deliver quality content in line with how people, around the world, rate information.”
What the ratings are for
But so what are these human interventions actually for? Sullivan explains further, revealing that last year alone Google “performed over 383,605 search quality tests and 62,937 side-by-side experiments with our search quality raters to measure the quality of our results and help us make over 3,600 improvements to our search algorithms.”
Live experiments
Added to these two types of feedback is another system used to make improvements: Google needs to “understand how a new feature will work when it’s actually available in Search and people use it as they would in real life.” To make sure it can get this information, the company tests “how people interact with new features through live experiments.”
These live tests are “actually available to a small portion of randomly selected people using the current version of Search,” and “to test a change, we will run a feature on a small percentage of all the queries we receive and look at a number of different metrics to measure the impact.”
It’s about getting answers to questions like “Did people click or tap on the new feature? Did most people ignore it? Did it slow down the page load?” which generate insights that “can help us understand a little bit about whether that new feature or change is useful and whether people will actually use it.”
Also last year, Google “ran over 17,000 real-time traffic experimentb to test new features and improvements to search.” Compare this number to the actual number of changes made (about 3,600, as mentioned earlier), and it becomes clear how “only the best and most useful enhancements land in Google Search.”
The goal of delivering increasingly useful results
Admitting that “our search results will never be perfect,” Sullivan concludes by saying that, however, “these search and evaluation processes have proven to be very effective over the past two decades,” enabling Google to “make frequent improvements and ensure that the changes made represent the needs of people around the world who come looking for information.”
