
The benefits of dynamic rendering on the SEO
In recent years JavaScript frameworks have become increasingly popular, thanks in large part to the flexibility they offer: despite the progress, however, when search engine crawlers visit scripted websites like AngularJS, React, Vue.js or jQuery it is possible that they do not “see” content like browsers actually do afterward, and this can cause indexing problems or even worse. There are, however, some ways to better communicate the site and bots, and especially the technique of dynamic rendering seems to offer the best answers to translate the content and structure of the site in the language preferred by crawlers.
What is dynamic rendering
Dynamic rendering is an exclusive pre-rendering for search engine robots: while regular site visitors are served normal client-side rendered content, crawlers receive a static HTML version of the pages, served in server-side rendering.
It is, therefore, a system that allows a different visualization of the site based on the type of user agent that performs the call, distinguishing between the normal client-side version of the site for users and the one designed specifically for Googlebot, Bingbot and other bots, which can then access, scan and index content without running JavaScript.
History of dynamic rendering
The concept of dynamic rendering was officially introduced by Google in 2018, although many sites were already adopting similar techniques through self-produced solutions or using third-party software: at the Google I/O conference in 2018, John Mueller defined dynamic rendering as “the principle of sending users normal client-side rendered content and sending fully server-side rendered content to search engines”.
Bing has also started to suggest this practice, proving how dynamic rendering can be a useful solution for a “historical” problem such as rendering and, in particular, the execution of some JavaScript frameworks.
Although search engines like Google and Bing can process JavaScript, in fact, they face limitations in trying to do so on a large scale; moreover, Google’s HTML crawler is not always able to process JavaScript, and then Googlebot can put such a page in a queue, waiting for the rendering resources to become available to render the whole page – and this also applies to Bingbot.
Google’s recommendation: use dynamic rendering as a temporary solution
However, we must emphasize an important point, also highlighted by a recent update of Big G’s official documentation to this technical aspect: for Google, dynamic rendering is an alternative solution to the problems of crawling and indexing Google Search with JavaScript, and therefore not the definitive and recommended method, because it generates additional complexity and requires more resources.
In fact, this is the position Google has taken from the beginning, but it was necessary to reiterate and mark it more sharply after the constant advances in Web and crawling technology (and the ever-increasing use of JavaScript), to try to convince developers, webmasters, and SEOs to implement alternatives to dynamic rendering, i.e., server-side rendering, static rendering, or hydration. In these cases, in fact, all meaningful content is displayed on the Web site’s server, and both users and bots receive a fully loaded page without the need to request additional resources.
How dynamic rendering works and what sites it serves
Dynamic rendering is not needed by all sites, therefore, but it is a possible alternative solution for those hosting pages with public indexable content generated with JavaScript that changes rapidly or uses JavaScript features not supported by major crawlers.
JavaScript rendering is user-friendly, but not bot-friendly, especially when crawlers are faced with large Web sites, because there are still limitations to processing JavaScript at scale while minimizing the number of HTTP requests.
Implementing this mode therefore has the advantage of overcoming this, as it allows search engine bots to access content without having to render it.
Differences with client-side rendering
In talk at SMX Next, Nati Elimelech (Wix’s tech SEO lead) provided an overview of how JavaScript works for client-side, server-side and dynamic rendering, highlighting some interesting aspects reported by this article on Search Engine Land.
The first step is to understand what happens with client-side rendering: when a user clicks on a link, his browser sends requests to the server on which the site is hosted. In the case of JavaScript frameworks, that server responds with something slightly different, because it provides an HTML structure, which is “only basic HTML, but with a lot of JavaScript, telling the browser to run JavaScript to get all the important HTML”. The browser then produces the displayed HTML – the one used to build the page the way the end user actually displays it.
According to Elimelech, this process resembles the assembly of Ikea furniture, because in practice the server says to the browser: “These are all the pieces, these are the instructions, build the page”, thus moving all the hard work is moved to the browser instead of the server.
Client-side rendering can be great for users, but there are cases where a client does not run JavaScript and therefore the user agent cannot get the full content of the page: when it happens to Googlebot or a search engine crawler the situation is obviously dangerous for SEO, because it can preclude the visibility of the page among SERPs.
Features of server side rendering
For clients that do not run JavaScript, you can use the server-side rendering, which moves on the server the execution of all “all that JavaScript”; all resources are required on the server side and the user’s browser and search engine bot do not need to run JavaScript to get the HTML fully rendered. Therefore, server-side rendering can be faster and less resource-intensive for browsers.
Using the same analogy as the previous example, Elimelech explains that “server-side rendering is like giving guests a real chair to sit on instead of pieces to assemble”, and when we render server-side we basically make HTML visible to all types of bots and clients, which will see “the important final rendered HTML” regardless of JavaScript capabilities.
Understanding how dynamic rendering works
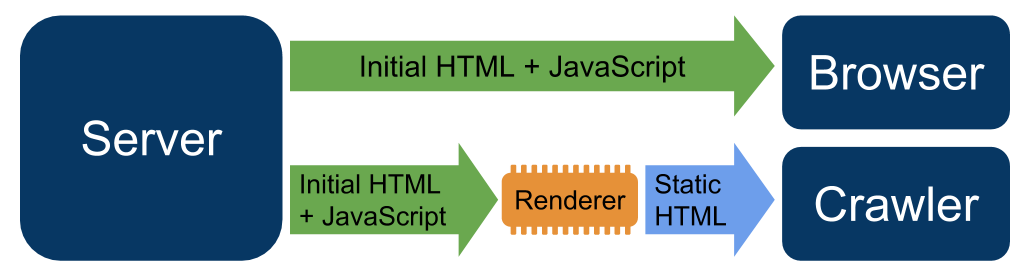
In this sense, dynamic rendering represents “the best of the two worlds” previously described, says Elimelech, because it allows the “transition between client-side rendered content and pre-rendered content for specific user agents”, as this diagram also explains.

In this case, the user’s browser executes JavaScript to get the HTML displayed, but still benefits from client-side rendering, which often includes a perceived increase in speed. On the other hand, when the client is a bot, the server-side rendering is used to serve the HTML completely rendered and “sees everything that needs to be seen”.
Thus, site owners are still able to offer their own content regardless of the client’s JavaScript capabilities; since there are two streams, they can also optimize them individually to better serve users or bots without affecting each other.
Which sites need dynamic rendering
As said, is Google itself to describe what types of site “must use dynamic rendering”, which is useful for public indexable content generated with rapidly changing JavaScript or for content using JavaScript features not supported by crawlers that are considered important.
Today, JavaScript frameworks allow for rapid development and provide a better user experience, because they deliver better performance and advanced features that traditional, non-JavaScript frameworks cannot achieve; so it is no surprise that very large websites or complex user interfaces, with complex logics and functionality usually tend to use JavaScript frameworks.
More generally, it is advisable to adopt dynamic rendering if the site is large and publishes rapidly changing content that requires rapid indexing, such as an e-commerce site with inventory that changes frequently; obviously, if the site relies on modern JavaScript functionality to generate part or all of the content and tries to ensure full indexing of the pages, which users can then find among search engines; if the site is based on social media and chat applications that require access to the content of the page.
If we still have doubts about the possibility of implementing dynamic rendering – which, it is worth underlining, is an alternative solution for crawlers and not an obligation – we can then analyze what are the conditions of ownership with respect to two issues such as the crawl budget and the render budget: if we have problems with such factors, and therefore if search engine bots do not find the important content, using dynamic rendering could actually be an optimal and faster solution than implementing server-side rendering.
The importance of dynamic rendering for SEO
From what we wrote it is clear that dynamic rendering is essentially an SEO JavaScript solution to allow search engines to properly process pages that otherwise would not be able to run.
Bots are based on static HTML elements and not on graphical interfaces that are obvious to humans: with dynamic rendering, client-side pages are translated, made completely accessible and served to search engine bots in their preferred static HTML format, so that they can access, understand and immediately index the contents to be found in the searches.
As Google explains, dynamic rendering requires the web server to detect crawlers (for example, with user agent control); crawler requests are addressed to a renderer, user requests are handled normally. If necessary, the dynamic renderer publishes a crawler-friendly version of content, such as a static HTML version.
Historically, JavaScript-based websites face some difficulties emerging in Search because they are easy to use but not bot-basedfriendly; this may also depend on the limited budget crawl of the Google search bot and the resource-intensive nature of JS content rendering. When search engine crawlers encounter heavy JavaScript content, in fact, they often have to index in multiple waves of scanning and this fragmented process results in missing elements, such as metadata and canonical tags, which are essential for proper indexing.
Dynamic rendering does not create cloaking issues
The implementation of this solution, moreover, does not cause any problem of understanding Google: for a long time, SEO feared that providing substantially two different pages to users and bots could fall under the same definition of cloaking, known black hat tactic exposed to penalties, but the official guide of Mountain View’s search engine reassures us on this front,
“Generally, Googlebot does not consider dynamic rendering as cloaking” even if it generates similar content, we read in the document; similarly, it does not evaluate as cloaking the generation of error pages, which Googlebot considers as any other error page.
Different is the case of using dynamic rendering to show completely different content to users and crawlers, such as “if a website shows a page about cats to users and a page about dogs to crawlers”, because this can be considered cloaking.
But, beyond the last example deliberately forced, in other circumstances it is a matter of providing Google with similar data on a page the way it wants, that is, in a format that can scan and index quickly, easily and economically.
How to implement dynamic rendering
The autonomous implementation of dynamic rendering can be difficult, time-consuming and resource-intensive, but it is still possible, as explained in Google’s guide with general guidelines to follow.
First, it is possible to adopt this solution for all pages or for individual pages, but each configuration is specific and varies depending on the implementation.
To ensure a practical approach, Google has activated a codelab that enables dynamic rendering implementation with Rendertron, an open source solution based on Chromium headless.
- Install and configure a dynamic renderer to turn content into static HTML code, which is easier for crawlers to use. Some common dynamic renderers are Puppeteer, Rendertron and io.
- Choose the user agents you want to receive the static HTML code and refer to specific configuration details on how to update or add user agents. Here is an example list of common user agents in the Rendertron middleware:
export const botUserAgents = [
‘googlebot’,
‘bingbot’,
‘linkedinbot’,
‘mediapartners-google’,
];
- If pre-rendering slows down the server or you see a large number of pre-rendering requests, evaluate the implementation of a cache for pre-rendering content or verify that requests come from legitimate crawlers.
- Determine whether user agents require content for mobile or desktop devices. Use dynamic publishing to provide the appropriate desktop or mobile version. This is an example of how a configuration can determine whether a user agent requires desktop or mobile content:
isPrerenderedUA = userAgent.matches(botUserAgents)
isMobileUA = userAgent.matches([‘mobile’, ‘android’])
if (!isPrerenderedUA) {
} else {
servePreRendered(isMobileUA)
}
In this example, use if (!isPrerenderedUA) {…} to publish content displayed on the client side. Use else { servePreRendered(isMobileUA)} to publish the mobile version if necessary.
- Configure your server to provide static HTML to the selected crawlers. There are many ways to do this, depending on the technologies at your disposal; here are some examples:
- Proxy requests from crawlers to the dynamic renderer.
- Pre-render as part of the implementation procedure and have the server provide static HTML to crawlers.
- Integrate dynamic rendering into your custom server code.
- Provide static content from a crawler pre-rendering service.
- Use a middleware for your server (for instance, the rendertron middleware).
The main problems with dynamic rendering
Dynamic rendering may be a viable avenue for websites with heavy JavaScript (generally difficult to scan) and for tasks that thus depend on JavaScript, but as mentioned it has some limitations and issues.
The first critical aspect concerns the complexity of managing the system, which requires technical expertise and care in implementing the “alternative” version of the pages to be served to the bots – with, moreover, no benefit on the user experience, since users do not perceive any of this “work.”
Often, therefore, this mode of rendering risks being neither economically sustainable nor from the point of view of the effort required of the development team, without considering the potential practical problems one may run into in the process.
There are three Google tools that can help us verify that the implementation of dynamic rendering is working properly, namely the Mobile Optimization Test, the URL Inspection Tool, and the Advanced Media Results Test, which allow us to analyze, respectively, whether the site is working for users on mobile devices, whether desktop content is also visible on the page displayed by Googlebot, and whether that structured data is being displayed appropriately.
On the other hand, when these tools report errors or we verify that pages are not appearing in Google Search results, it is time to analyze the causes of the problem, which according to Google generally fall into 4 cases:
- The content is incomplete or looks different
This error stems from a misconfiguration of the renderer or incompatibility between the web application and the rendering solution, but sometimes timeouts can also cause a content rendering error.
- High response times
This case depends on the use of a headless browser for rendering on-demand pages, which often causes high response times and, therefore, may cause crawlers to cancel the request and not index the content. High response times can also lead crawlers to reduce the crawl rate while crawling and indexing content. To solve this problem, we can configure and enable a cache for pre-rendered HTML or create a static HTML version of the content as part of the build process, and then verify that crawlers can quickly access the content and that requests do not timeout.
- Web component rendering does not occur as expected
This happens if Shadow DOM is isolated from the rest of the page: rendering solutions (such as Rendertron) are unable to see content within the isolated shadow DOM. The solution is to load polyfill webcomponents.js related to custom and shadow DOM elements, then verify that the contents appear in the displayed HTML code of the rendering solution.
- Missing structured data
A missing structured data user agent or JSON-LD script tags in the output can cause errors in the structured data; to solve the problem, we need to check that JSON-LD script tags are included in the HTML with dynamic content rendering.
