
SEO solutions to improve URL parameters
Let’s complete our focus on URL parameters: we already saw what query strings are and to which risks an ineffective site management could lead, so now is the time to discover all the best pratices to avoid any further problem. There are six ways to try and improve URL parameters and make them more and more SEO friendly, keeping an head start of filters and strings without bothering usability, crawl budget and SEO optimization.
Eliminate unnecessary URL parameters
Limit your resort to unneeded URL parameters: the easier process is to detect how and why parameters are generated and then identify the ones that are truly adding value to both users and the site from the ones that reveal themselves as useless, at best, if not downright detrimental to SEO.
We can then eliminate unnecessary query strings (the most unused filters, those parameters that do not operate useful functions, the kind of tracking that can be rendered easier by cookies), avoid the materialization of blank values, pay extra attention to never apply multiple parameters with the same name but different value, closely look after these elements’ arrangement.
Use the rel canonical to give pages hierarchy
We already dwelt on the use of rel canonicals, so all we can really add is that this kind of operation surely has some benefits (such as the simplicity of implementation, the high warranty of avoiding content duplication problems and the chance of reinforcing ranking signals on the preferred URL), but negative aspects too. After all, even with the canonical one could waste crawl budget on the parameters’ pages, and sometimes Google could decide not to use the cue (we were talking about it a few times back); moreover, it is not enforceable on all kinds of parameters.
Setting Noindex directives on Meta Robots
The third type of operation concerns meta robots and the chance to block research indexing with a “noindex” tag, that as we know is Google’s recommended method to achieve this goal (having officially retired the noindex in robots.txt files!).
We could now set a noindex directive on each page that does not really add SEO value, so to avoid for it to be listed inside the search engine’s index; furthermore, there is also the chance that “no index”-tagged URLs will undergo scans less frequently and, eventually, Google could automatically decide to put on nofollow the page’s links.
The benefit of this solution lies in its simplicity and efficiency on preventing content duplication; plus, we could apply it on all those kind of URL parameters we wish to rule out from the index and to remove pages already indexed by Google. At the same time, though, the Noindex directive on Meta Robots is seen by the search engine as a strong hint rather then straight obligation, and for that this does not actually forbid Googlebot and other crawlers to scan pages, only assures for it to be done less frequently; quite obviously, then, ranking signals provided by the site will not be reinforced.
Using the Disallow on Robots.txt file
One more available path would be using the Disallow directive on the robots.txt file, that stands as the absolute first element search engines look for onsite before any scan: once they find this specific, they will steer clear from pages. In this same way it is possible to block crawlers the access on any page with URL parameter or to singularly specify those query strings we don’t want to be indexed.
We are again talking about a pretty easy technical implementation, with immediatly positive effects and suitable for any kind of parameter: with the help of the disallow we can generate a more efficient management of the crawl budget and avoid content duplicates. The downsides, though, are the inability to reinforce signals for the ranking and, above all else, to remove pre-existent URLs from the Index.
Using URL Parameters tool in Google Search Console
Inside Google’s webmaster tools there is a feature that allows you to manage all these elements: it is simply called “URL Parameters tool” and is dedicated to all those websites that use URL parameters on unrelevant page’s variations (for instance, color=red and color=green) or on parameters that allow to basically display the same contents with different URLs ( like, example.com/shirts?style=polo,long-sleeve and example.com/shirts?style=polo&style=long-sleeve)”, as we can read in the guide to avoid “an ineffective scan of the site”.
It is important to investigate how to use this tool the best way possible, because is the exact same page written by the Google’s team to highlight a warning message: a wrong usage could bring actual damages to the site and its ranking position on Google Research, given the fact that the search engine “could downright ignore important pages of your site without any warning or notification of the ignored pages. If that seems a bit drastic is because so many people use the tool the wrong way or without a real need. If you have any doubt on the tool’s correct use, it could be then better not using it at all“.
What is Google’s Url parameters tool actually for
The tool forbids Google to operate the scan on the URLs that include specific parameters or parameters with specific values and, as on other cases, we need it to avoid that the crawler could operate the scan on duplicated pages. Its effects are very straightforward: the “parameters’ behaviour applies to the property as a whole” and it is not “possible to limit the scan behaviour of a determined parameter to an URL or specific part of your site”.
When to use Search Console’s tool, the requirements
According to Google, there are two predicaments that should lead us to use URL Parameters tool: a website with over a thousand pages and (at the same time) a high number of duplicated pages indexed by Googlebot into the log in which only URL parameters are different (for instance, example.com?product=green_dress and example.com?type=dress&color=green).
How to use the tool
The key question to face this aspect is “how is the parameter influencing the page’s content?”, on which depends the best way to manage settings and subsequently optimize the SEO performance of the pages.
As default setting for well-known parameters there is the chance to let Googlebot decide how to actually manage them: the crawler analyzes the site and determines which is the best and more efficient way to go. For the ones that instead want to have full control on the operations, it is possible to decide to never block URLs with a specific parameter, to only submit URLs with determined values to the scan and to totally block the scan based on specific parameters.
Generally, among pros of this tool we can surely highlight its usability, that doesn’t nibble off any time to developers ( and, entrusting tasks to Googlebot, not even to the site’s manager); moreover, it is well-suited for any kind of URL parameter, can prevent content’s duplication and allows a more effective use of the scan’s budget. There are some cons, though: first of all, similarly to other interventions it does not reinforce ranking signals and it is not a mandatory directive, but it mainly works for Googlebot only and for that does not send the same messages to alternative search engines crawlers, like Bing.
Only choose statical URLs
Our last solution is very drastic and takes time: we would need to convert every single URL parameter into statical URL rewriting all server-side addresses and using redirect 301. On the other hand, according to many, the best way to manage query strings is to downright avoid them all, also because subfolders help Google understand the site’s structure and statical URLs based on keywords have been a milestone of SEO on page.
An approach with benefits and limits
This approach works well with descriptive parameters based on keywords, like the ones identifying categories, products or filters for relevant features to search engines, and it is effective on translated contents too. Anyhow, things become problematic for those elements whose keyword is not really relevant, as the price, where having a filter such as a statical and indexable URL that does not offer any real SEO value. Furthermore, it is tricky for research parameters too, given the fact that each user-generated query would create a statical page that could degenerate in cannibalization relative to the canonical, or yet again to present to crawlers low quality content pages every time a user looks for a not-existent article.
This path is not that useful, not even with the tracking (Google Analytics will not recognize a statical version of the UTM parameter), and above all replacing dynamic parameters with statical URLs for things such as impagination, onsite research box’s results or the ordering do not solve the duplicate content, the crawl budget or link juice dilution.
Getting to the point, for many websites is not possible nor recommendable to completely eliminate parameters if the final goal is to provide an ideal user experience , neither would be the best SEO practice. For that, a compromise could be to implement query strings for parameters that must not be indexed into Google Research, and to instead use statical URLs for the most relevant parameters.
It is not a matter of a single perfect solution to manage URL parameters
Based on what already written it should be clear by now that a perfect solution to effectively manage URL parameters both for user experience and SEO does not exist, because everything depends on the evaluations directly tied to the site: in some cases it could be more important to optimize the crawl budget compared to the reinforcement of the ranking signals, while in others priorities will follow the opposite way.
SEO optimization of the query strings, the path
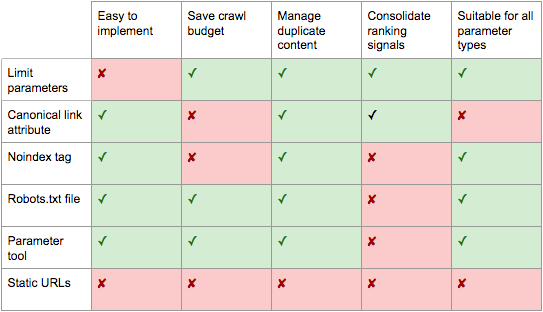
Broadly speaking, an average path of SEO friendly optimization of the query strings could be the following, suggested by Jes Scholz on the Search Engine Journal (from which we extracted the summary image on pros and cons of all previously described solutions):
- Launch a keyword research to identify wich parameters should be statical URLs and could be potentially positioned on search engines.
- Implement the correct management of the page layout with Rel=prev/next.
- For every other Url with parameters, implement cohesive rules of ordering, that use keys one single time and forbid blank values to limit the number of URLs.
- Add a canonical to the pages of parameters that have any chance of ranking.
- Set up the configuration of URL parameters both on Google and Bing as preservation to help search engines understand the function of each parameter.
- Control that URLs based on parameters are not being sended on the Sitemap
