
Google Webmaster Conference, SEO suggestions and inspirations
Not only SMXL19 and SEO Doomsday: last week (farther away than Milan!) there was a second huge field meeting as well, with the Google Webmaster Conference taking place for the first time ever right inside Mountain View’s headquarter. Barry Schwartz on Search Engine Land covered the event and gathered both inspirations and indications from the meeting, so let’s see together which were the main points speeches had focused on (and, for that, what Google actually wanted to share with over 200 attendees).
Google Webmaster Conference’s main topics
Schwartz spotted a total of five interesting themes, particularly about:
- Structured Data
- Research with the emojis
- Deduplication Advices
- Suggestions on crawling and rendering
- Synonyms management
Actually, there wasn’t any staggering announcement, but the Googlers explained in further details how the whole Google system works, hence providing the needed support to SEO specialists to plan their daily activity, as well as to think about future strategies based on the newest trends. Here is what was highlighted (pic from twitter).
The structured data’s value
The true importance of structured data for any site should be more than known by anyone by now, but to be definitely sure we just need to linger a bit more on the work Google has redirected on this factor for years. From this year’s webmasters conference we understood that the commitment is high and there could soon be an increase in the support of further structured data markups to provide new in-SERP rich results and to offer info both on search results and Assistant’s vocal researches .
Practically speaking, this means that there should be added whole new types of rich results besides the rest of the already officially supported options, as well as that Google is actually working to enhance and update how these kind of info are truly displayed inside Google’s search results pages.

Google includes emojis too!
Our second issue could seem just a little fun fact, but it is not like that: after a year-long work, now Google is finally able to scan, index and rank emojis inside the Research system; furthermore, it was revealed that at the time being Google sees more than a million researches per day that include emojis in the search sentence!
Then we go back to the on page optimization advices with the “deduplication suggestions”, a.k.a those kind of strategies needed to avoid content duplication problems (such as keyword cannibalization). This session’s interventions explained how the search engine manages duplicated contents and how webmasters can help Google understand which is the page’s canonical version to considerate.
Indications in this regard are:
- Use redirects (that are “almost perfectly predictive of duplicated contents”, according to Mountain View’s engineers).
- Use HTTP status codes
- Checks rel canonical links.
- Use hreflang for localization.
- Flag hijacking cases on forums.
- Safe Dependencies for safe pages.
- Keep canonical signals and URL reinforcements unambiguous.
Rendering and fetching management
They talked about tecnical SEO too and, to be specific, about scanning, rendering and indexing; even if in this case Barry Schwartz summed up the most useful cues gathered throughout the session.
- Do not rely on caching rules, Google never follows them.
- Google keeps fetches to the lowest, so GoogleBot could not be fetching on everything.
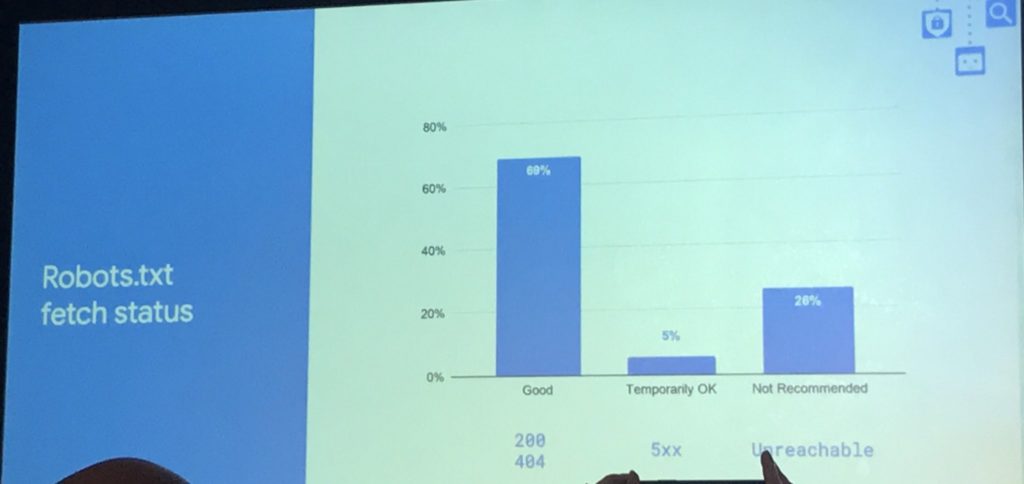
- Google checks on file robots.txt before operating the scan.
- 69% of the times Google receives a 200 response code whenever trying to access robots.txt, 5% of the times 5XX response code, 20% of the times that robots.txt is unreachable.
- A 200 response code id ideal, but even a 404 status could be good because it is interpreted as a lacking of crawling restrictions. Instead, if Google does not reach the robots.txt file due to a not temporary 5xx error (and after different trials and errors), Google will not operate the site’s scan.
- Google works on the rendering of what you normally see using the Chrome browser.
- Google does 50-60 resource fetches per page, i.e a cache percentage of almost 60-70%, or 20 fetches per page circa.
Google and synonyms, how the search engine is evolving
The latest focus concerned the evolution of Google’s algorithm on contents comprehension (mainly right after the Google Bert launch) and Paul Haahr, one of the leaders of Google’s Search section, focused his presentation both on synonyms and how Google understands some questions, also recounting some of the old errors the search engine used to commit and that have now long been corrected. Among quoted examples there is the one about gm query, that has different meanings according to the different context the term is in: General Motors, genetically modified and general manager. Analyzing the contest of the page, Google would now be able to determine which is the intended meaning therefore cataloguing the content at its best.
