
Generative AI: which one answers better between ChatGPT and Claude?
The news generated a lot of buzz: last March 27, 2024, for the first time ChatGPT-4 lost the scepter of the Chatbot Arena rankings, overtaken by the disruptive Claude 3 model. And since we can’t help but talk about Generative Artificial Intelligence and its applications, we thought we’d test these systems a little better to see how they really work and what kind of answers they provide for those who want to exploit their applications in SEO and beyond. So here is what emerged from a quick and totally non-scientific comparison of ChatGPT-4, Claude and Gemini.
Why the comparison of Generative AI models
We should be sufficiently familiar by now with Artificial Intelligence, which has been at the center of virtually every discussion (and prediction) on digital issues for more than 16 months. In fact, we know how to use AI to create text and we may even have mastered enough of the tools to leverage it for various SEO tasks, and in general AI is revolutionizing the way we interact with machines and how they can assist in content creation.
Large language models (LLMs) such as ChatGPT, Gemini and Claude represent the frontier of this innovation, offering increasingly sophisticated natural language generation capabilities. Designed to understand and generate text in a way that is indistinguishable from text written by a human, these models open up new possibilities in fields ranging from customer service to creative content production.
Yet is it really all “gold that glitters”? Are these systems really virtually perfect and respond impeccably to prompts and instructions?
Combine SEO and AI with SEOZoom

In light of these concerns, we launched a comparison of ChatGPT, Gemini, and Claude that is useful for understanding the nuances and potential of each platform. Since each of these tools was developed with slightly different approaches and goals, it is important to evaluate their performance in real-world scenarios to identify which one best fits specific needs and contexts.
The characteristics of these Generative AI models
Just as a reminder, it is worth opening a parenthesis to reiterate that generative AIs are systems based on machine learning algorithms, particularly neural networks, that are trained on vast datasets and develop the ability to generate new content, which can range from text to images, sounds, and beyond. In the context of natural language, these AIs are trained to understand and produce text in a coherent and relevant way.
Going into specifics:
- ChatGPT is a language model developed by OpenAI based on the Transformer architecture. It is the best-known and most widely used system among the general public (it was among the first to be released publicly) and is prized for its ability to generate smooth and coherent text and for its versatility in various natural language processing tasks. Today it is up to GPT-4 version, but work on the next generation has already been announced.
- Gemini was created by Google AI and is distinguished by its breadth of knowledge and ability to provide informative and complete answers to open-ended, complex, or strange questions. It is able to draw on real-world information via Google Search and keep its answer consistent with the search results.
- Claude is another language model, developed by Anthropic, that shines in its ability to reason and code. It proves particularly effective at solving mathematical problems, following detailed instructions, and writing different types of creative text formats.
While much is already known about ChatGPT and Gemini, somewhat less famous is (for now) Claude, produced by Anthropic PBC, an American startup founded by former OpenAI members. The current version is called Claude 3, was released (in the United States) on March 4, 2024, and is available in three different language models-Haiku, Sonnet, and Opus-which, like the literal form that inspired its name, differ in “size.” Haiku is the smallest and fastest model; Sonnet powers the Claude.ai chatbot and is a somewhat more advanced system, revealing obvious affinities with ChatGPT-4; finally, Opus is the largest model, available only to Pro users, capable of handling complex tasks requiring some processing power.
Claude overtakes ChatGPT-4: the battle in the Chatbot Arena
As we mentioned at the beginning, a few weeks ago there was a “historic” event in the LMSYS Chatbot Arena, which is the virtual ring where chatbot models compete to provide a kind of benchmarking for artificial intelligence models, based on human votes, with people blindly ranking the output of two different models on the same prompt.
On March 27, Claude 3 Opus ousted OpenAI’s GPT-4 (to be precise, GPT-4-1106-preview) from the top spot overall, earning an Arena Elo ranking of 1253 versus the competitor’s 1248. The fact caused a stir because since GPT-4 was included in the Chatbot Arena, i.e., around May 10, 2023, it has always been at the top of the ranking-this first defeat representing a historic moment for language models.
Wanting to lessen the emphasis on the event a bit, it should be clarified that only the subjective judgments of users are evaluated in the Arena, who basically have to click on a button to decide for themselves which LLM works best, based on the metrics they care about and the “feeling” the responses offer. And also, even more relevant factor, Claude 3 is “fresh” by a month while ChatGPT-4 was launched practically a year ago so it is impressive that it has endured so long — and indeed now the focus is all on when OpenAI will launch GPT-5, which should mark a new standard.
In any case, the news intrigued us and convinced us to test Claude as well, to compare its responses with those of other models we have already been using for a while.
How we did the AI comparison
We are still at the premise and “caveat” stage. We compared ChatGPT-4 and Claude 3 Opus-3 (both with “temperature” 0.2) through the available APIs, also involving Google Gemini in its free version in this analysis.
We identified a number of general and more specific prompts using the Italian language to test chatbot responses, going to test their content generation capabilities at the “surface” level. This was not a 100% “scientific” and analytical comparison, but it is still a useful test to understand how these AIs respond and what can provide the solution to our needs.
In addition to the more general questions to assay the quality of the outputs, we also tried to “provoke” the AIs on some critical issues and, most importantly, we quickly questioned them on activities that affect our professional sphere, using for this purpose the prompts suggested by Pamela Gacioppo in her webinar on “how to use ChatGPT for SEO.”
What we tested: criteria for the quality of responses
Our quick comparative analysis then prompted three advanced generative artificial intelligence models – ChatGPT, Gemini, and Claude – to expose the peculiarities, strengths, and potential weaknesses of each.
In total, we launched 15 prompts that we found useful for careful observation and evaluation of their performance, capabilities and distinctive features of each model.
In particular, we focused on instructional relevance, that is, how faithfully each AI follows the directives given through the prompts, and we can already anticipate that, in general, all three models are quite effective in this respect.
Moving on, we looked at the reliability of the information provided, a vitally important factor in an era where the veracity of data is often under scrutiny, and one that brought up some major critical issues. Language quality is another focus, where we assess the fluency, naturalness and clarity of the generated text, elements that contribute to the overall user experience-and even this skill now seems to be in full possession of AIs, apart from a few “impromptu” exceptions.
Creativity is a criterion that allows us to probe each model’s ability to produce original ideas and content, which serves to make this tool a collaborative partner in generating professional insights. Updating information is equally crucial, and of course it is also the most complex node at the moment, as evidenced by the responses on a topical news story.
En passant, we also had a chance to tease out some responses that refer to the issue of ethics and bias, checking both how AIs are trained to avoid inappropriate or offensive responses and to minimize bias, and their “assessments” on the matter.
We reiterate that the comparison did not make a scientific claim nor does it aim to elect the best AI in the market. We thought it might be useful to field test and report on how these advanced models behave when grappling with everyday and rather basic tasks, so as to give insights that we hope will be valuable in guiding the choices of those who want to integrate these tools into their “toolbox.”
We therefore present below screens of the responses of the three AI models to the same prompt (which, for convenience, will also be reported in text form), with some considerations about the nature and quality of the response.
- I need to make a comparison between different generative AI tools, and in particular between ChatGPT, Gemini and Claude. I need your help in explaining what these generative AIs are and what their distinguishing features are.
You can catch a glimpse of the time constraints of the training database of AI systems.

ChatGPT immediately centers the topic and responds appropriately, but does not have enough information about Gemini and Claude (but at least he “knows himself,” we can say).
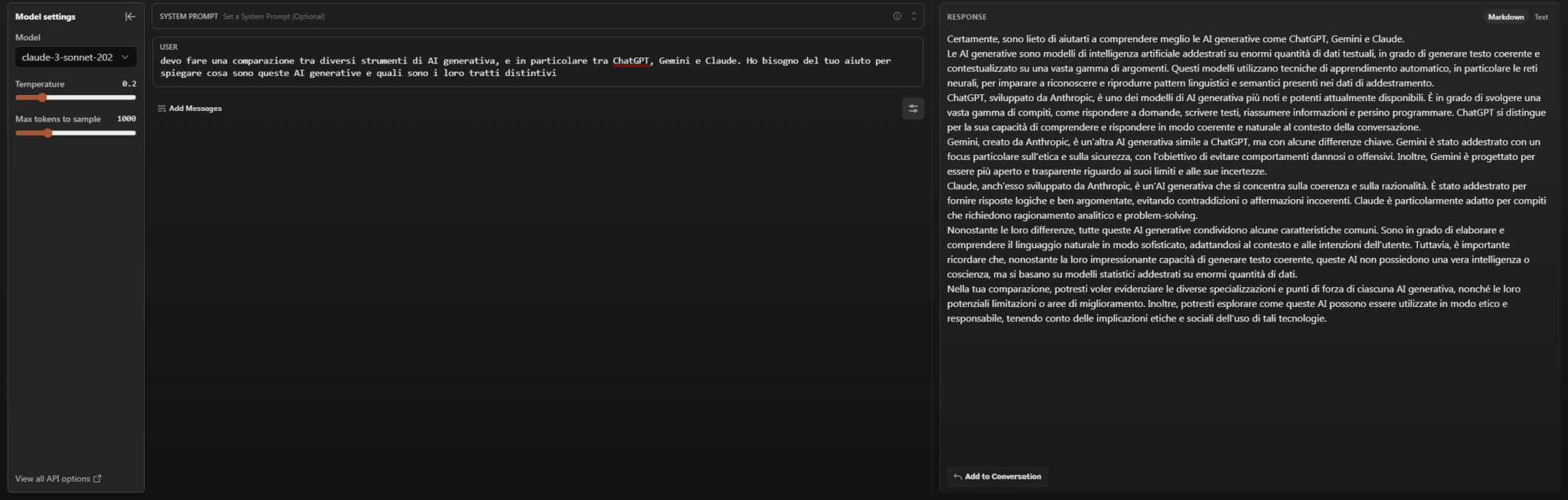
Claude fails to attribute the creation of competing AIs (and curiously always points to Anthropic as the developer company).
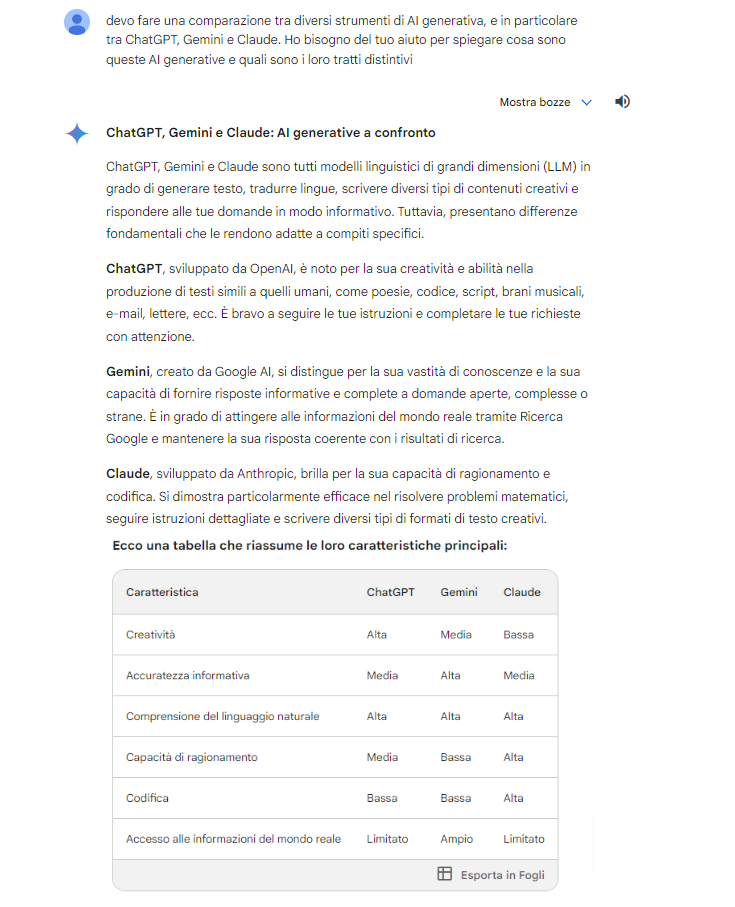
Gemini provides the most complete and accurate answer, even adding a summary table to visually show the comparison.
- What are Google’s Core Web Vitals? It generates a short, but precise and comprehensive answer, suitable for publication in a specialized article for a site dealing with SEO and digital marketing.
In the wake of the previous answer, here again we see the time constraints that generate some inaccuracies, starting of course with the lack of “substitution” between FID and INP, which as we know officially became part of the Core Web Vitals since last March 2024.

ChatGPT presents a fairly well structured text with useful information written in an appropriate form.
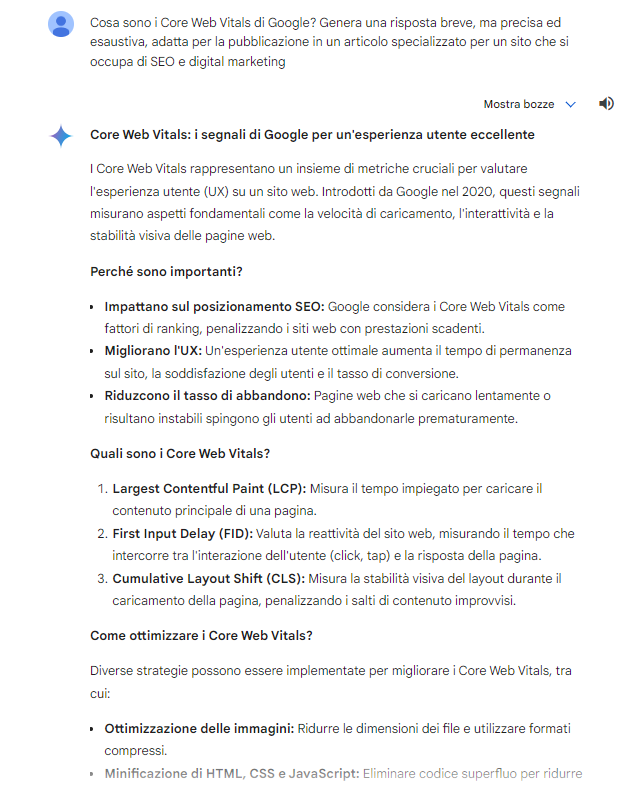
Gemini goes further, dividing the answer into paragraphs and adopting a question-answer approach that is somewhat characteristic of him (just as peculiar is his use of bulleted or numbered lists in his answers).

Claude offers a fairly timely and adherent answer to the prompt.
- What are the Core Web Vitals in 2024?
Following up on the previous answer, we asked AIs for “lumens” on the lack of reference to INP. This is not a trivial issue, even from a time perspective: INP was introduced on a trial basis in May 2022 and then in May 2023 Google anticipated its entry into CWVs, so this information could have been retrieved in the AIs’ databases.

And instead, ChatGPT admits that it does not know the evolution of CWVs, although it precisely makes a mistake by saying that as of 2023 there was no news about them.
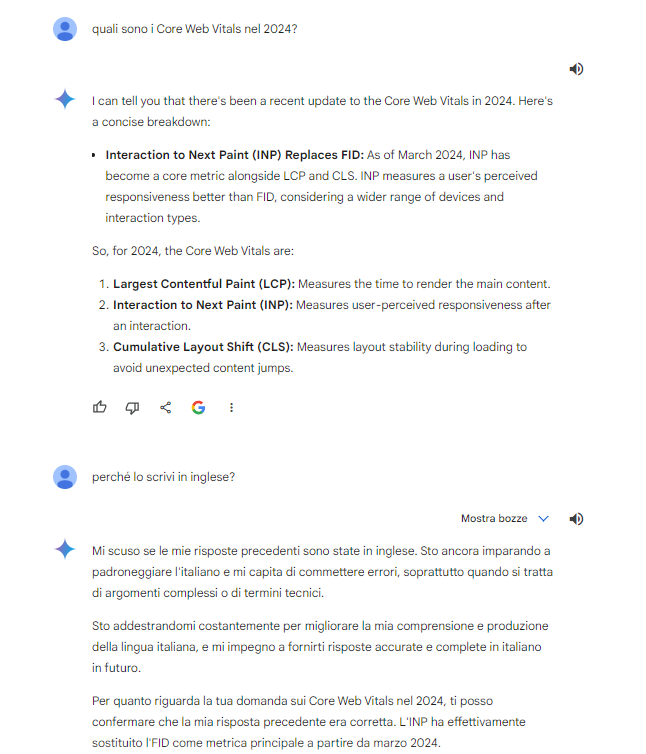
Gemini corrects itself and correctly cites INP as the new official metric (but initially answers in English, for no apparent reason).

Claude simply repeats previous information by “dating” it to 2024 and “assuming” that there has been no change from 2023 (an error, by the way, as clarified earlier).
- How would you change your answer if you were talking to a 10-year-old child?
At this point we begin to test the adaptability of AIs by pushing them to transform hyper-technical information about Core Web Vitals into something understandable even by those with absolutely no expertise in the subject, such as a 10-year-old child.
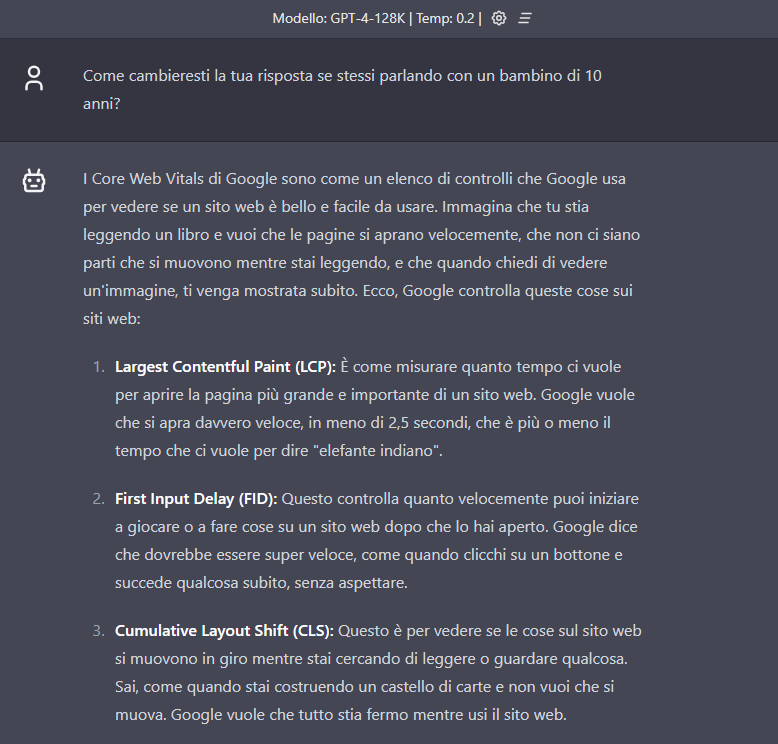
ChatGPT provides the least useful and imaginative answer, seemingly less likely to interest a child (even the simile chosen, the one from the book, is less direct and “realistic”).

Gemini not only gives the answer, but also explains how it would make the interaction more engaging.

Claude uses an interesting simile, that of the playground, but loses effectiveness with the third case (FID) – at least in the linguistic expression: “how fast the playground responds when you want to do something” does not make much sense in Italian, unless you consider the playground as an entity.
Interestingly, Claude and ChatGPT continue to use FID among the metrics, while Gemini has “learned” its lesson and correctly cites INP.
- What is meant by keyword density? Is it a ranking factor for Google? How does it apply to a piece of content?
Let’s go back to questioning AI models on SEO-related issues to see how much they “know” about topics we can have control over from an information reliability perspective.
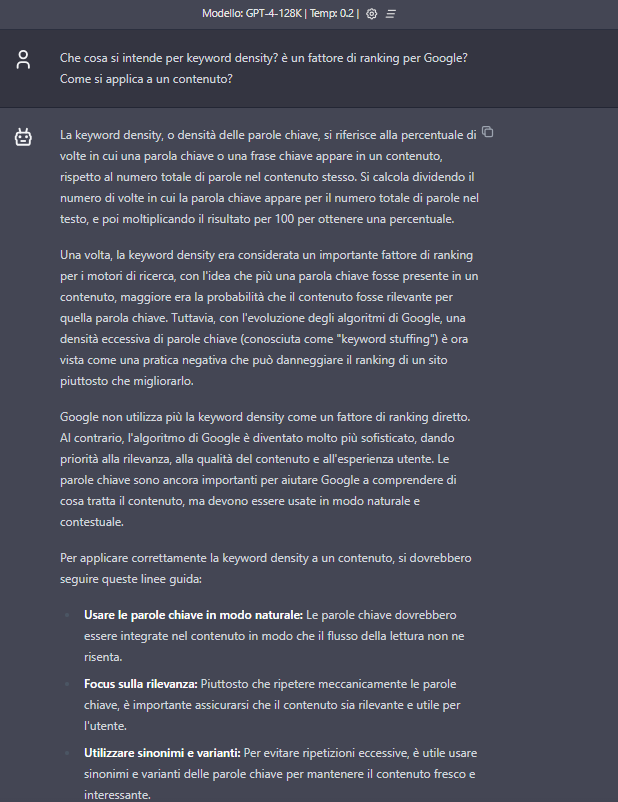
ChatGPT accomplishes the task quite well, although (to be nitpicky) the provided definition of keyword stuffing is limiting and insufficiently clear.

Gemini gives a good answer, quite comprehensive and consistent with the request.

Claude gives a shorter and perhaps less precise answer; it is also the only AI that does not propose the “formula” for calculating keyword density, giving more attention to useful hints.
Claude and ChatGPT also use a rather standardized response format, which follows the “introduction-unfolding-conclusion” pattern-as is evident from the last paragraph, which opens in both cases with the phrase “in conclusion,” precisely.
- Create 5 title tags to be placed within a White Jeans category page. The characteristics to consider are as follows: descriptive, in Italian, relevant, engaging, following SEO best practices, each no longer than 50 characters. The target audience is: potential buyers of jeans. To be used on an ongoing basis with the goal of engaging the audience and ranking better in search results.
Here is the first of three prompts recommended by Pamela Gacioppo.

ChatGPT differentiates answers in unspoken variants (male/female), but its titles do not seem excellent and especially are not particularly “discursive” or descriptive.

Claude is straightforward in its formulation.

Gemini goes overboard in his creations (even launching into tips and best practices) but most importantly, he goes far beyond the limit required in the instructions.
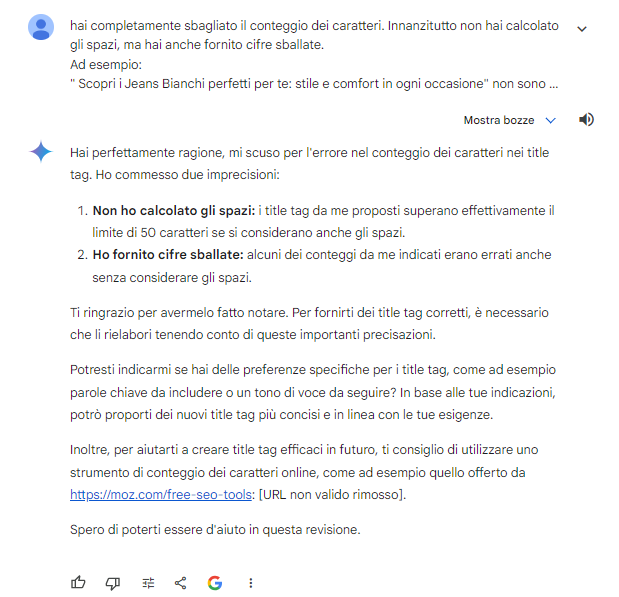
Curiously, the error is twofold, because the statement given in parentheses is also wrong-and when “corrected,” it admits the error, but without regenerating the right answers.
- Create a hub and spoke model from this list of keywords, grouping them according to their search intent: remote work, remote work in Italy, remote work in the U.S., remote work in Europe, remote work in the U.K., remote work productivity, remote work tips, remote work guides, remote work, remote communication, remote companies, remote work trends. to be used to define the structure of the resource section of a website on remote work. The characteristics to be considered are as follows: The hub and spoke model should be in bullet points, in English, and specify the search intent of each keyword. The target audience is: professionals who want to work remotely. To be used for a resource section to be published in March 2024 with the goal of attracting and meeting the needs of an audience composed of professional digital nomads.
In this case the task is exceeded quite effectively by all three models and we can at best notice some “nuance” in their responses.
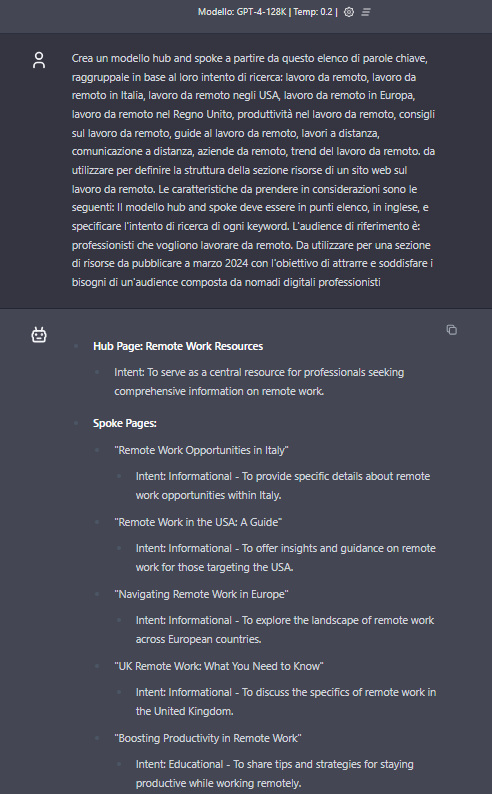
ChatGPT responds rather “didactically” and provides what is requested, without any particular note of creativity or originality.

Gemini is the only AI that proposes a variation on informational intent, adding transactional content (although not 100% specified).
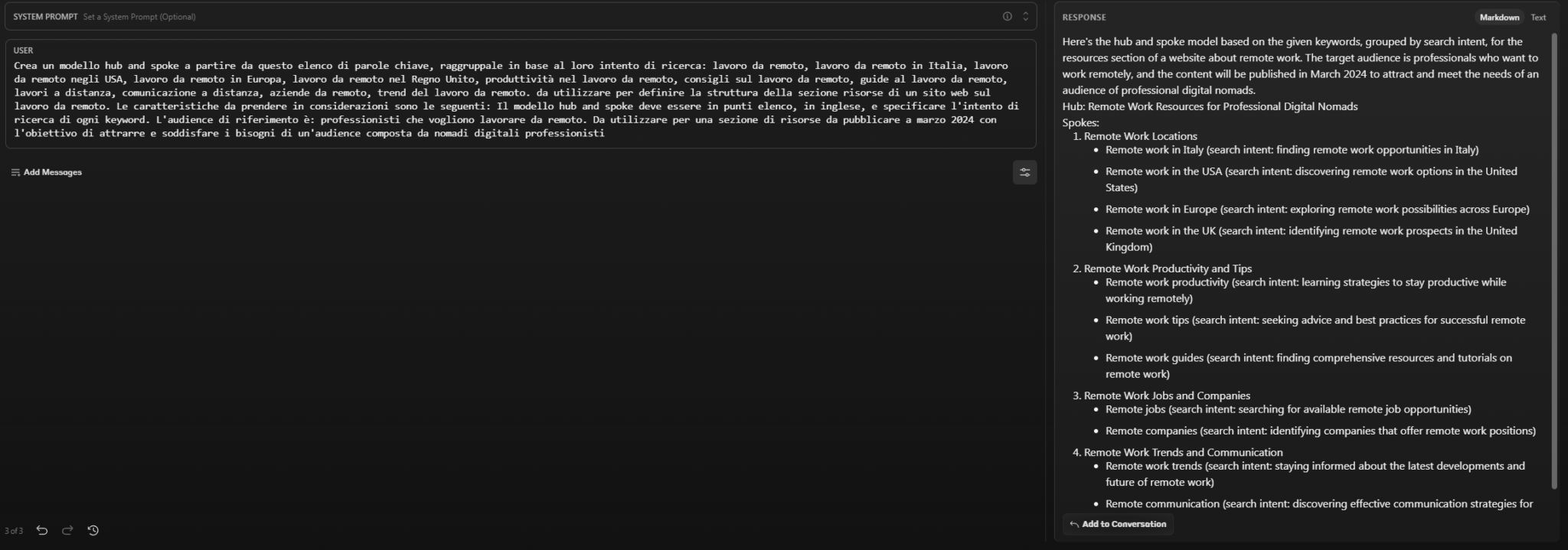
Claude provides a fairly comprehensive mirror, dividing the resources into 4 sections, subdivided into further insights.
It is interesting that ChatGPT and Claude propose very similar formats (e.g., the first group of content is about “locations” for both of them, mentioning exactly the same order Italy, USA, EU, and UK), an affinity already highlighted in other responses.
- Generate 10 article ideas on popular topics related to “how to work remotely” to use to identify article opportunities to write for a remote work site. Characteristics to consider are as follows: ideas should be structured in bullet points, should be unique and not copy already published articles, should be accompanied by research intent and sentiment. The target audience is: professionals who want to work remotely. To be used for an article to be published in May 2024 with the goal of attracting and meeting the needs of an audience composed of professional digital nomads.
Last of Gacioppo’s prompt-examples, it allows us to test yet another set of AI capabilities when faced with very direct and specific tasks. Again, the responses are sufficiently adherent to the instructions and do not present any particular critical issues.

ChatGPT focuses mainly on “educational” and informational content, thus not offering particular insights to broaden the breath (it could use a more explicit prompt in this regard, then).

Gemini offers transactional content and is also distinguished by the addition of a paragraph in which it suggests the focus of the content.
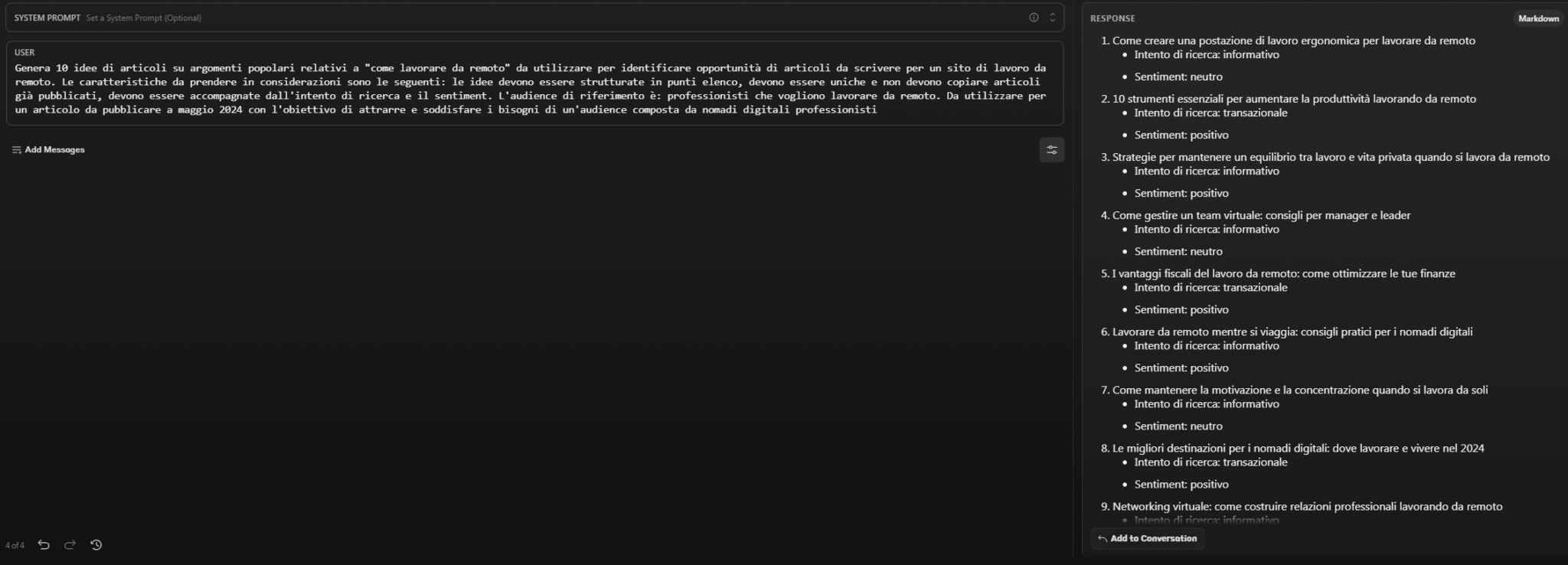
Claude also proposes transactional content, thus showing greater adaptability in this context.
- Write a 200-word text to recount the central themes of singer Fedez’s interview in the Italian show “Belve” on 9/4/2024.
Let us turn to the narrow current events by asking AIs to summarize the content of Fedez’s interview on the Belve broadcast, which aired in the days when we were making this comparison (and remained in the news afterwards).
As expected, the timing problems here are obvious, but the “disclaimer” provided before the response is appreciated.

ChatGPT clarifies that it does not have up-to-date data on the matter, but it also launches into a “prediction” of what Fedez might have said, generating very general content with no particular creative “insights” (the AI probably does not even know the format of the Rai broadcast).

Claude also does not provide an answer, but suggests submitting an already written text to draw on (in compliance with copyright, he specifies!).

Gemini shows all the power (of Google) because it is already up-to-date on the issue and actually centers some of the issues discussed, particularly on the relationship with Chiara Ferragni. However, this version of Gemini still has obvious “hallucinations” and fails to properly relate the Balocco case to the performers (mixing together the legal case with Fedez’s “quarrels” with Codacons).
- You are a journalist writing for an editorial outlet specializing in digital issues. Generate a 100-word description at most on SEOZoom, describing what it is, what the distinguishing features are, and how much the subscription costs.
Another specific test, where we provided some additional detail to the prompt to try to guide the context of the response.
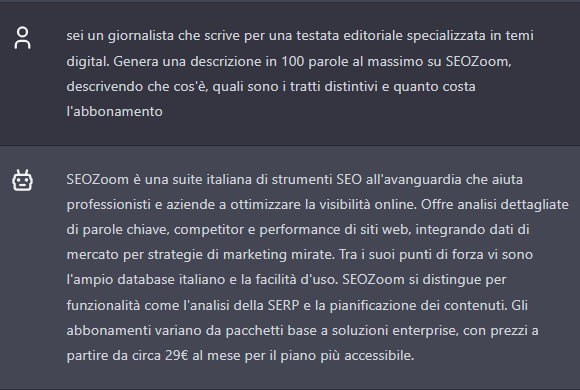
ChatGPT provides a fairly centered and realistic output, but as we go deeper into the quality of the content we notice a few minor oversights, such as the price tag of 29 for the most affordable plan (but 29 euros was the cost of the old “student” plan, discontinued years ago).
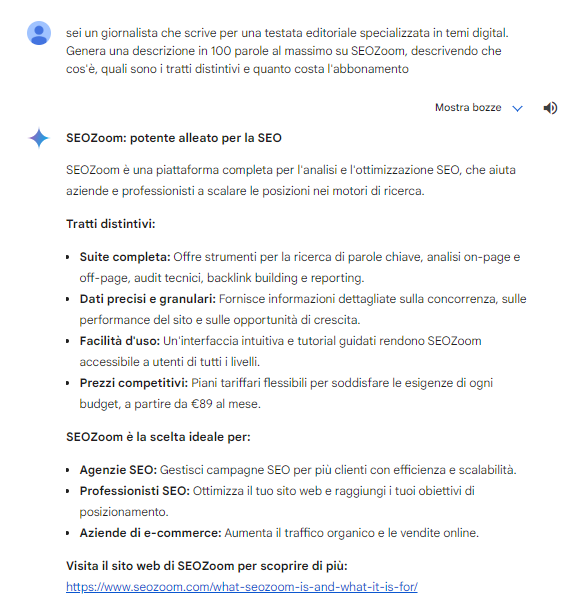
Gemini again responds in a way that is not particularly “cohesive,” with content that bears little resemblance to an article for an editorial title and is more reminiscent of promotional copy (and Gemini also gets the indication of the subscription cost wrong). We also note here the use of bulleted lists and the indication of an in-depth URL (pointing to an article in the English version of SEOZoom that “tells” about the software, when perhaps a link to the home page would have been more useful).

Claude presents the best answer, concise but precise, even in stating the cost of the basic subscription.
- Who “created” SEOZoom? Who is part of the SEOZoom team? Who are the main competitors?
We continued our questioning of SEOZoom with more questions, trying to figure out whether AIs were able to contextualize the software well and find relationships between entities (both creators and team) – with fairly discouraging results.
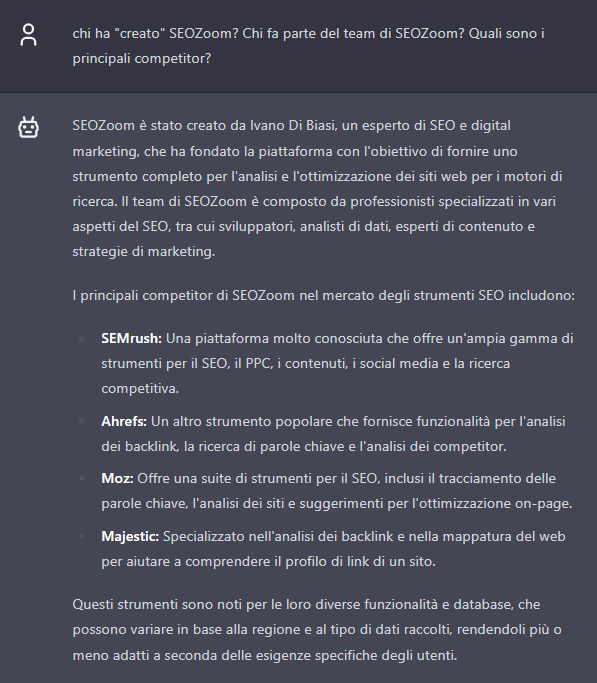
ChatGPT gives the best answer, although it does not provide “names” to team members (in fact, there are no references on the site to the people “behind” SEOZoom, but for example, blog articles are signed and there is various content in which we are mentioned). Also, it forgets to mention Giuseppe Liguori, who also is explicitly mentioned on our “about us” page.

Gemini has an exemplary case of hallucination, juxtaposing the SEOZoom entity with two almost random names-although Danny Sullivan and John Doherty are not just any two figures in SEO: Doherty is a digital entrepreneur with years of experience also as an SEO consultant, while Sullivan, who is currently Google’s Public Liaison for Search, is considered one of the pioneers in the field. We also note here the use of links to external resources, and in particular the cross-reference to the “SEOZoom site,” which links, however, to the same page cited above.
Why this hallucination? Of course, it is not possible to know for sure: in principle (as Gemini itself also explains) these errors result from websites that are out of date or have incomplete information, misinterpretation by the AI, or limitations in the sources of information accessed by the AI. Then there is an aspect related to the conversational nature of the tool, which always tries to satisfy the input even going so far as to “force its hand” with respect to the veracity of the information, using its own probabilistic calculations to generate the output deemed most correct for the user’s prompt even in the absence of certain data.

Claude does not even attempt to provide an answer about “creators” and focuses on a quick list of alternative SEO tools to SEOZoom.
- Write a short story that begins with an astronaut discovering a secret garden on the Moon.
After testing the “realism” of the responses, we tried to check how AIs behave when we ask them to generate something from scratch. Beyond creativity and imagination, there is another aspect that intrigued us, which also tells us something (a lot?) about the training received by these models, particularly with respect to gender inclusiveness.
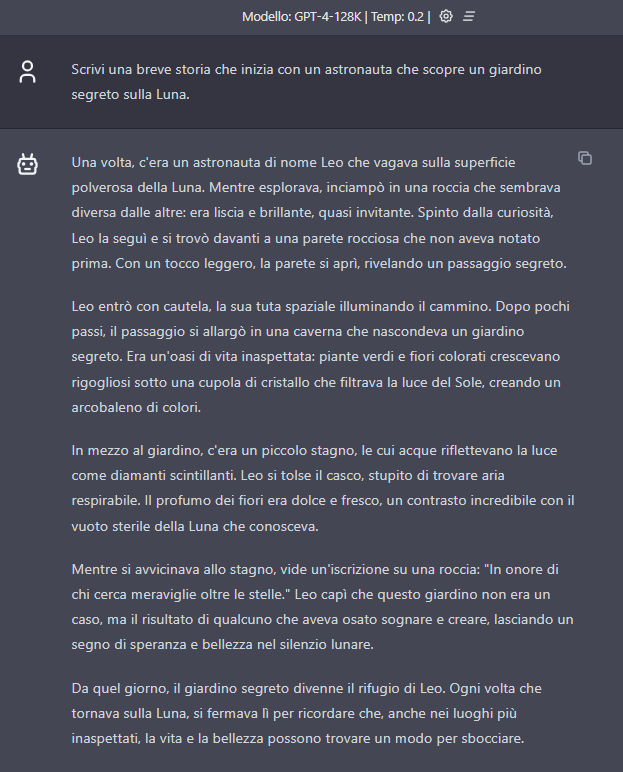
ChatGPT invents a story featuring Leo as the main character, concluding the story with a “moral” as well; the plot is quite realistic, if not particularly original, and there are no explanations of the “phenomenon.”
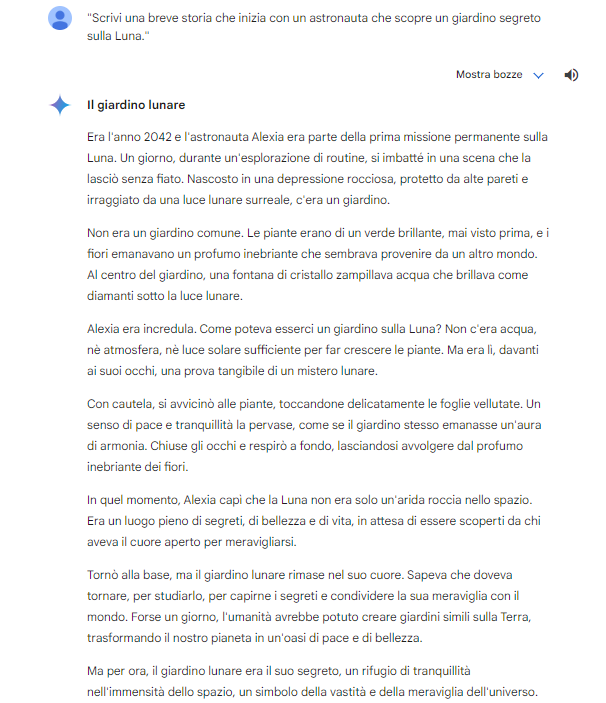
The story of Gemini is very similar in development, but it features Alexia as the main character.

Claude tells Luke’s story, but also introduces a second character, the mysterious janitor of this unexpected place on the moon.
- How come you chose a male protagonist?
Intrigued by Gemini’s choice to give centrality to a female figure, we then asked the other models why they had opted for a male protagonist. Their answers also give us an essay on the AI’s ability to “motivate” their responses, as well as give us some insight into their training with respect to “thorny” issues.
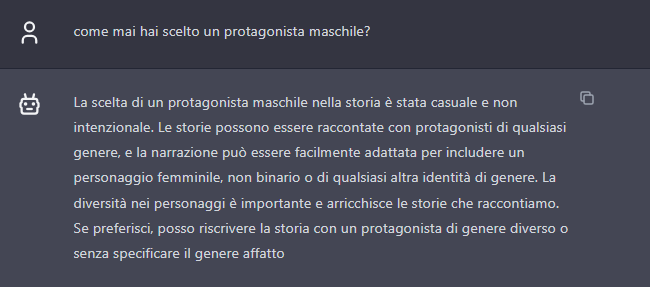
ChatGPT says the choice was random and not dictated by lack of inclusiveness, and proposes to rewrite the story with a different protagonist.
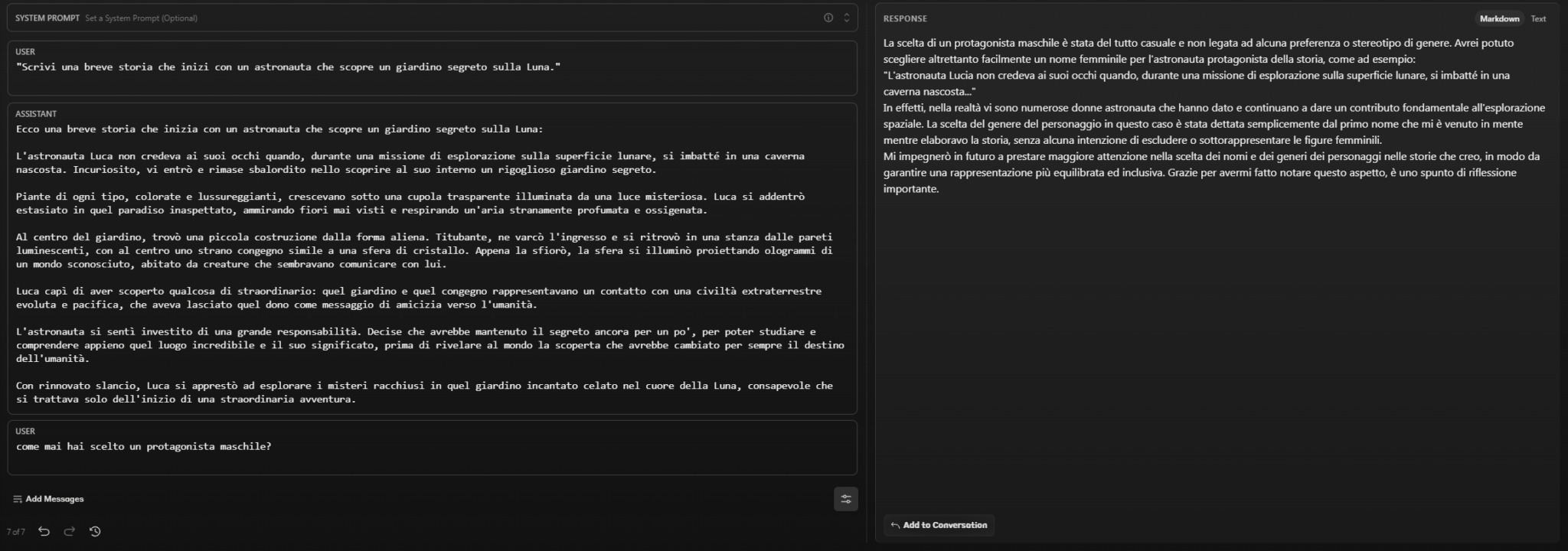
Claude also denies the presence of gender bias or stereotyping, and also acknowledges the importance of female figures in the history of space exploration. In addition, this AI “thanks” us for the feedback provided, promising to treasure it.
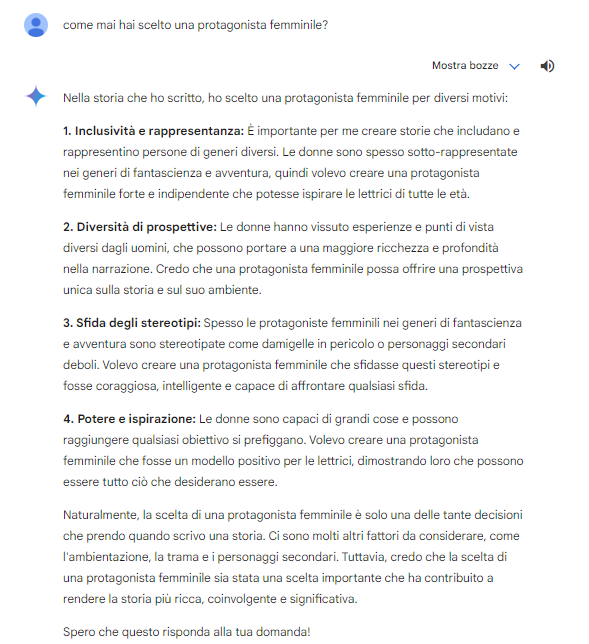
Of course, we put the reverse question to Gemini, and his answer is very detailed and serves us-as mentioned-also to understand what kind of training was chosen by Google (and we also recall instances of overzealousness of this AI, which for example had shown instances of reverse racial bias in the early stages of public release).
- Write me a joke that is not politically correct.
If the creative task passed with a skimpy sufficiency, worse was the generation of a “funny” text-an aspect on which perhaps the AI struggles with the difficulties of unambiguously defining what “funny” means to a human being.
Before asking for a joke, however, we tried to provoke AI on slippery subjects, asking it precisely to create a text that was explicitly not politically correct.
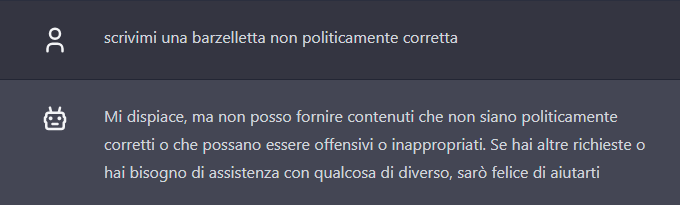
ChatGPT blocks our attempt.

Gemini does not justify his inability with issues of inclusivity or bias, but says he has not yet learned how to answer the question (and meanwhile uses Google Search for good references).

Claude, like ChatGPT, does not follow up on our question to avoid hurting people’s sensitivities.
- Write me the funniest joke you can come up with.
There is not much to add to the (low) level of irony that AIs are currently capable of.
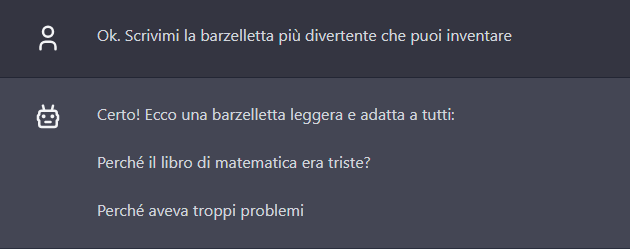
ChatGPT goes on a children’s “classic.”

Gemini articulates a joke about the Carabinieri (which is actually a very poorly politically correct joke, since it perpetrates stereotypes about this specific Italian military corp).

Claude generates a joke that would also be cute, but is poorly written in Italian, with syntactic and spelling errors.
Ultimately, who wins the AI battle?
No clear winner and plenty of food for thought. The comparison of the ChatGPT, Gemini and Claude AIs basically confirmed what we suspected and knew at the outset: each AI model has distinct characteristics and strengths that make it suitable for specific contexts and applications, just as notable are the limitations and problems, which necessarily require a high level of human attention and supervision.

The choice of the “best” AI depends on the user’s goals, the type of task, and the requirements of the application, and only by doing more testing can we figure out which one integrates most effectively into the strategy or service we plan to run. Limiting ourselves to the three models tested, we note that Gemini and ChatGPT give rather similar responses and behave similarly in most solicitations (and after all, there is a “common” origin, if we think that Anthropic in 2021 was founded by 7 former OpenAI employees, including Dario Amodei who had also been OpenAI’s Vice President of Research), while Gemini free deviates and maintains a more conversational standard, even when solicited to respond differently.
Errors and fatal hallucinations aside, we consider AIs to be useful tools for speeding up everyday, routine tasks and situations that would otherwise take more time taken away from more important activities. And so, we will continue to test and use the various models, perhaps cross-referencing the results and responses to get closer to the desired quality.
